
questionet
LLM Trend Note (4) InstructGPT : RLHF, 언어모델과 강화학습의 만남 본문
RLHF의 탄생배경
모든 일이 그렇듯, 어느날 갑자기 없던 게 생겨나진 않습니다.
우리가 보는 건 땅 위에 싹이 불쑥 튀어 나와 하루가 다르게 쑥쑥 자라나는 모습이지만,
싹이 트기 바로 직전까지 땅속에는 무수한 씨앗들이 꿈틀대고 있었을 테니까요.
RLHF (Reinforcement Learning Human Feedback) 에도 물론 히스토리가 있습니다.
그 전에, 눈에 보이지 않는 땅속에서 꿈틀거릴 수 있었던 저 씨앗들을 누가 뿌렸고,
그보다 앞서 저 씨앗들이 어디서부터 왔는지를 잠시 살펴보겠습니다.
ChatGPT라는 혁신적인 AI 모델이 지난 2022년 겨울 우리에게 찾아오기 훨씬 전부터
LLM이 풀지 못했던 커다란 숙제가 하나 있었습니다.
바로 알고리즘의 편향 또는 편향된 알고리즘 문제가 바로 그것입니다.
LLM은 어마어마한 양의 토큰을 먹어치웁니다.
2023년 초에 발표된 가장 최신 모델인 GPT-4와 비슷한 시점에 공개된 Meta의 LLaMA는
1.4T 개의 토큰을 학습했다고 앞선 노트에서 말씀드린 바 있습니다.

위의 그림에서 보듯이 CommonCrawl 데이터셋이 전체 데이터의 절반이 훨씬 넘습니다.
좀 더 정제된 C4까지 합치면 전체 구성의 80%를 넘게 차지하네요.
물론 위키나 서적, 연구 논문이나 기술 블로그의 내용들에도 정치적, 학문적, 문화적, 과학적 편향이 들어갈 수 있지만
원시 웹페이지에서 긁은 텍스트 데이터에 깃들어 있을 대중적 편향은 훨씬 그 기울기가 가파를 수밖에 없습니다.
편향을 둘러싼 예를 들자면 수도 없이 많습니다.
어텐션 레이어에서 "CEO"라는 토큰과 "남성"이라는 토큰에 높은 관련성을 부여하게 되거나
"요리", "청소" 같은 집안일을 "여성"과 결부시켜 학습하는 식의 이야기들이 모두 해당됩니다.
알고리즘 편향에 대해 관심이 있으신 분들은
앞선 노트에서 말씀드린 On the Opportunities and Risks of Foundation Models논문의
5절 society 이하 5.1.2 Harms의 Intrinsic biases 문단을 참고해보세요.
참고로 임베딩의 편향성을 제거하는 인상적인 시도를 연구한 논문도 소개해 드립니다.
상용화된 foundation model이 이런 편향을 간직한채로 서비스된다면
실생활과 밀접한 연관이 있는 고용, 대출 같은 영역에서 불공정한 결과가 초래될 수 있다는 점에서
알고리즘 편향 문제는 굉장히 심각하고, 진지하게 다뤄지는 주제입니다.
알고리즘의 편향을 필터링하거나 제거할 수 있는 방법을, 지도학습 기반의 단일 딥러닝 모델에 손실함수화할 수 있을까요?
대부분의 LM은 Cross Entropy 손실함수를 사용해 next token을 예측하는 방식을 사용합니다.
그리고 BLEU나 ROUGE 같은 평가 메트릭으로 모델의 추론결과를 사후 보정합니다.
이 프로세스가 RLHF 이전에 대부분의 LM이 알고리즘 편향을 극복하기 위해 채택했던 주된 방법론이었습니다.
이런 방식은, 학습단계에서 모델이 데이터의 편향을
고스란히 학습할 수밖에 없다는 한계를 여전히 짊어지고 있죠.
다시 말해 BLEU나 ROUGE 처럼, 인간의 선호가 반영된 메트릭의 사용이 loss function의 계산결과 자체에 여전히 영향을 주진 못한다는 말입니다.
바꿔 말해, 고전적인 지도학습 기반의 단일 foundation model만으로는
자신이 만들어낸 문장, 음성, 이미지, 영상 자체가 HHH 기준을 충족하는지 결코 자각할 수 없습니다.
모델이 윤리적으로 적절한지,
유해한 정보를 창발해내고 있는지를 손실함수 단계에서 걸러낼 수 없다면
모델의 훈련루프에 인간이 직접 참여하지 않을 이유가 없다...
이것이 RLHF라는 씨앗의 기원입니다.
그리하여 OpenAI는 라벨러들을 고용해 인간이 직접 그 씨앗을 모델에게 뿌리는 방법을 선택합니다.
RLHF는 OpenAI와 Deepmind의 연구자들이 2017년에 발표한
Deep Reinforcement Learning from Human Preferences논문에서 처음 소개되었습니다.
유명한 영상 하나를 첨부합니다.
영상에서처럼 위 논문은
Reinforce Learning을 사용해
가상환경에서 에이전트에게 backflip을 가르치는 과정에서
human feedback을 주는 게 목적이었습니다.
피드백을 주는 인간에게는 agent(모델)의 action(행동)에 대한 두 가지 옵션이 제공되고
목표달성에 가장 가까운 옵션을 선택해 피드백을 줍니다.
(즉 인간의 피드백이 environment에 속하게 됩니다)
human feedback 없이 순전한 강화학습만으로 에이전트를 학습시킬 때보다 훨씬 효과적이라는 걸 입증한 논문이었죠.
위 논문에 뒤이어 2019년에 발표된 Fine-Tuning Language Models from Human Preferences논문에서는
강화 학습을 텍스트 요약task를 수행하는 PLM에 적용했습니다. (깃헙 참고 링크)
좀 더 상술하면 TRL(Transformer Reinforce Learning) 을 구현하기 위해 요약 레이블과 ROUGE,
두 메트릭을 사용하여 강화학습 알고리즘인 PPO (Proximal Policy Optimization)를 적용할 수 있다는 걸 보여준 논문이었습니다.
그 뒤를 이어 2020년에 발표된 Learning to summarize from human feedback논문에서는
앞선 논문에서 사용한 두 메트릭에 인간의 선호도가 충분히 반영될 수 없다는 문제점을 지적하며
인간이 직접 품질을 비교한 데이터셋을 바탕으로
인간의 선호도를 학습시킨 모델 자체를
강화학습의 보상함수(reward function)로 사용할 수 있다는 아이디어를 제시합니다. (깃헙 참고 링크)
바로 이 부분이 핵심입니다.
일반적인 강화학습 시스템에서는 보상함수가
human feedback과 무관한 environment에 혹은 강화학습 알고리즘 내에 결정되어 있습니다.
agent가 자신의 action을 교정하는 방법이
envrionment 내지 RL algorithm에서 결정되는 action에 대한
reward와 state변화에 의존적이라는 것입니다. (아래 그림의 푸른색 박스)
그러나 RLHF에서는 보상함수가 envirionment/RL algorithm 에서 분리되어 있습니다.
나아가 그 보상함수는 human feedback을 학습한 별도의 모델로 존재합니다.
그리고 agent(모델)은 보상 모델이 주는 reward로 action을 개선해나가는 것이죠. (위 그림의 붉은색 박스)
따라서 Learning to summarize from human feedback 논문의 LM은
입력 데이터가 편향되었다 하더라도 알고리즘 편향없이
human feedback이 의도하는 품질의 요약을 수행하게 되는 것입니다.
위 그림과 아래 그림을 비교해보세요.
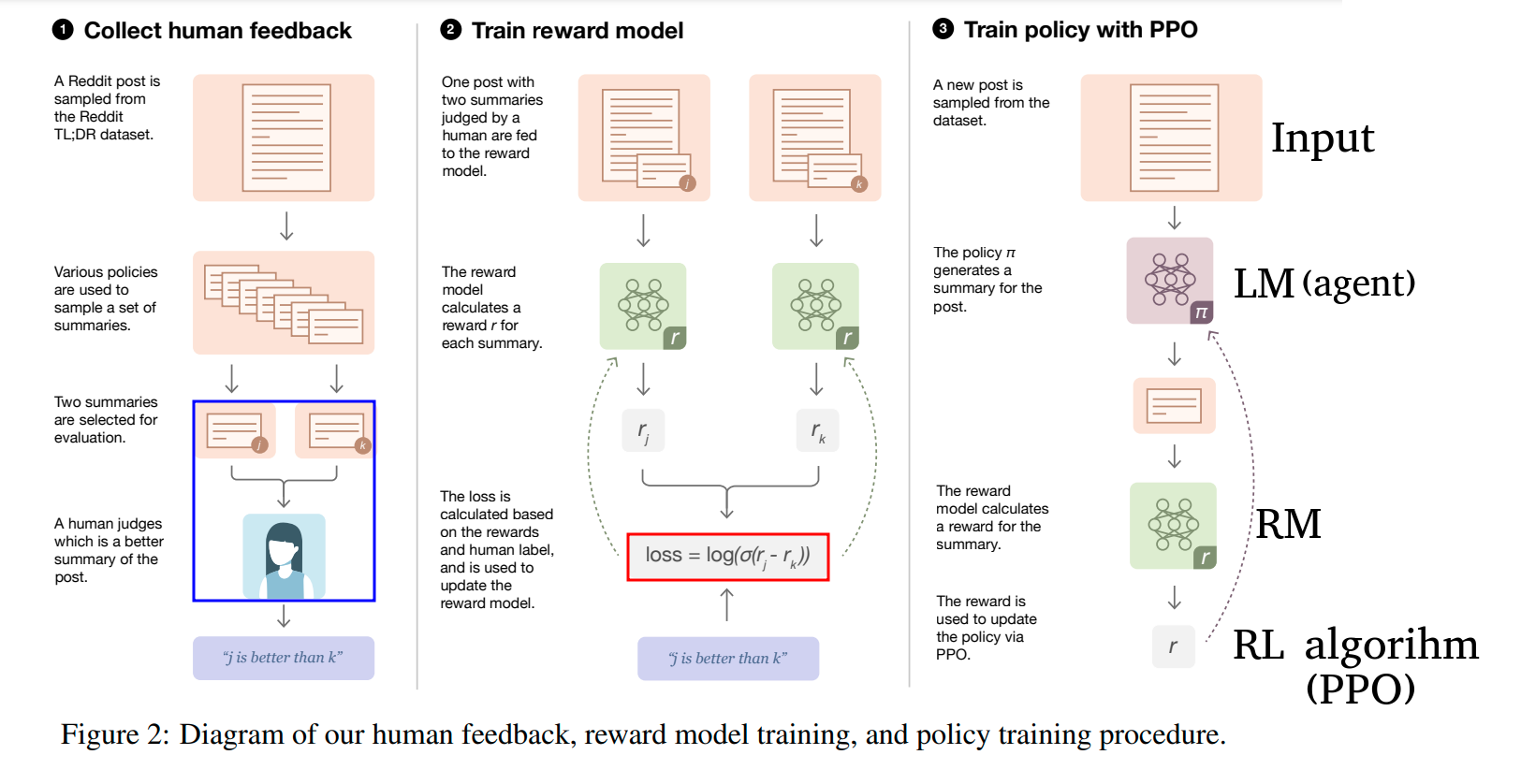
1단계 : Collect human feedback 에서 원문과 복수의 요약 쌍으로 이뤄진 데이터셋에 대해,
인간이 직접 고품질 요약과 저품질 요약으로 분류합니다.
하나의 원문에 대해 j와 k요약이 있을 때, "j is better than k"처럼 말이죠.
2단계 : Train reward model 에서 원문과 그에 상응하는 분류된 요약쌍들을
RM (reward model)에 넣어 각각의 reward를 계산하고
RM이 각 요약의 (human feedback이 반영된)품질을 매길 수 있도록 학습시킵니다.
위 그림의 빨간 박스 안에 있는 손실함수의 공식이 의미하는 바가 무엇일까요?
논문 Learning to summarize from human feedback의 6p에 있는 Reward Models. 부분을 발췌한 그림입니다.

3단계 : Train policy with PPO 에서 LM(agent)에은 새로은 원문을 입력받습니다.
그리고 훈련된 RM을 사용해 LM이 생성해낸 요약이 고품질 요약이 되도록,
다시 말해 인간이 더 선호하는 요약이 되도록 LM을 강화학습시킵니다.

논문에서 캡쳐한 위 설명에 따르면
LM에서 매 타임스텝마다 생성되는 토큰에 대해
PPO algorithm의 보상 R(x,y)를 maximize하는 방식으로 강화학습이 이뤄집니다.
(수식에 나온 음수항에 대해선 뒤에서 자세히 설명하겠습니다.)
PPO algorithm에 관한 자세한 내용은
OpenAI에서 2017년에 발표한 Proximal Policy Optimization Algorithms 논문과
허깅페이스의 블로그 의 Proximal Policy Optimization (PPO) 내용을 참고하세요.
이로써 chatGPT의 첫번째 버전인 InstructGPT가 탄생하기 위한 씨앗이 모두 뿌려졌습니다.
2022년에 발표된 Training language models to follow instructions with human feedback논문에서
드디어 LLM + RLHF의 프로토 타입인 InstructGPT가 세상 밖으로 나오게 된 것입니다.
InstructGPT
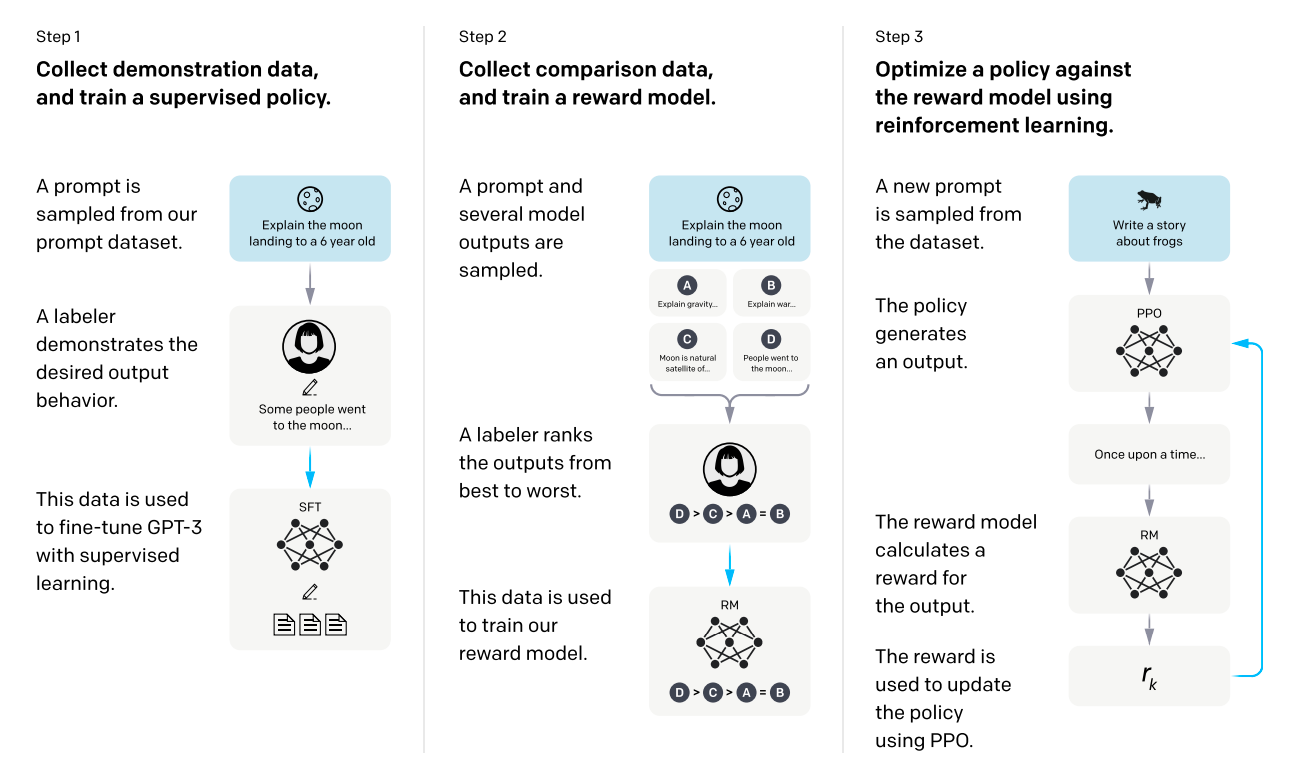
위 그림은 InstructGPT 논문에 실려 있는 모델 학습 개요도입니다.
Learning to summarize from human feedback 에서의 3단계 프로세스와 매우 유사함을 볼 수 있습니다.
이제 위에서 살펴본 RLHF의 탄생배경에 기여한 메커니즘들을 좀 더 구체적으로 살펴보겠습니다.
RLHF로 학습된 대표적인 LM은 2023년 초 기준으로 아래와 같습니다.
OpenAI : InstructGPT, ChatGPT
DeepMind : Sparrow
Anthropic : Claude
이중 우리는 InstruchGPT를 기준으로 살펴보도록 하겠습니다.
최적의 RLHF를 구현하는 방법이 무엇인지는 활발히 연구되고 있는 주제입니다.
공통적인 프로세스를 추려보면 아래 세 단계로 이루어진다고 볼 수 있습니다.
1. Pretraining a language model
2. gathering data and training a reward model
3. fine-tuning the LM with reinforcement learning
1단계 : SFT
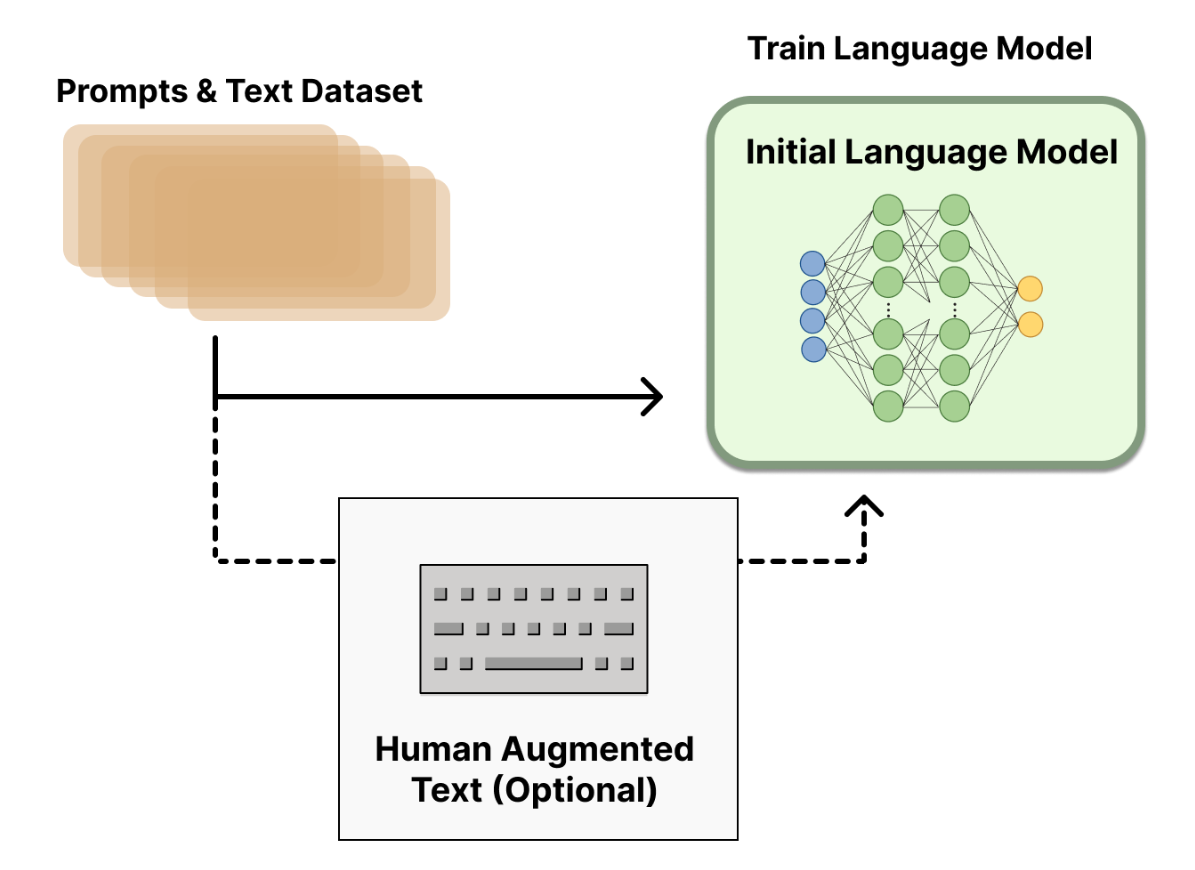
OpenAI에서는 human annotator를 고용해
prompt에 대하여 사람의 선호를 반영한 label 쌍으로 이뤄진 고품질의 데이터셋을 직접 구축하였습니다.
그 다음 1.3B, 6B, 175B 3가지 사이즈의 GPT-3에 위 데이터셋으로 fine-tuning 시켰습니다.
InstructGPT에 사용한 이 방법을 Supervised fine-tuning (SFT)라고 합니다.
반면 Anthropic에서는 10M, 3B, 12B, 52B 사이즈의 디코더 기반 트랜스포머를 사용한 점은 OpenAI와 유사하나,
원본 LM을 HHH기준에 맞게 context distilation한 LM을 사용했습니다.
(좀 더 자세한 내용은 Anthropic에서 발표한 A General Language Assistant as a Laboratory for Alignment논문의
2.1 Context Distillation를 참고하세요.)
한편 Deepmind에서는 280B 사이즈의 Gopher를 사용했습니다.
2단계 : RM
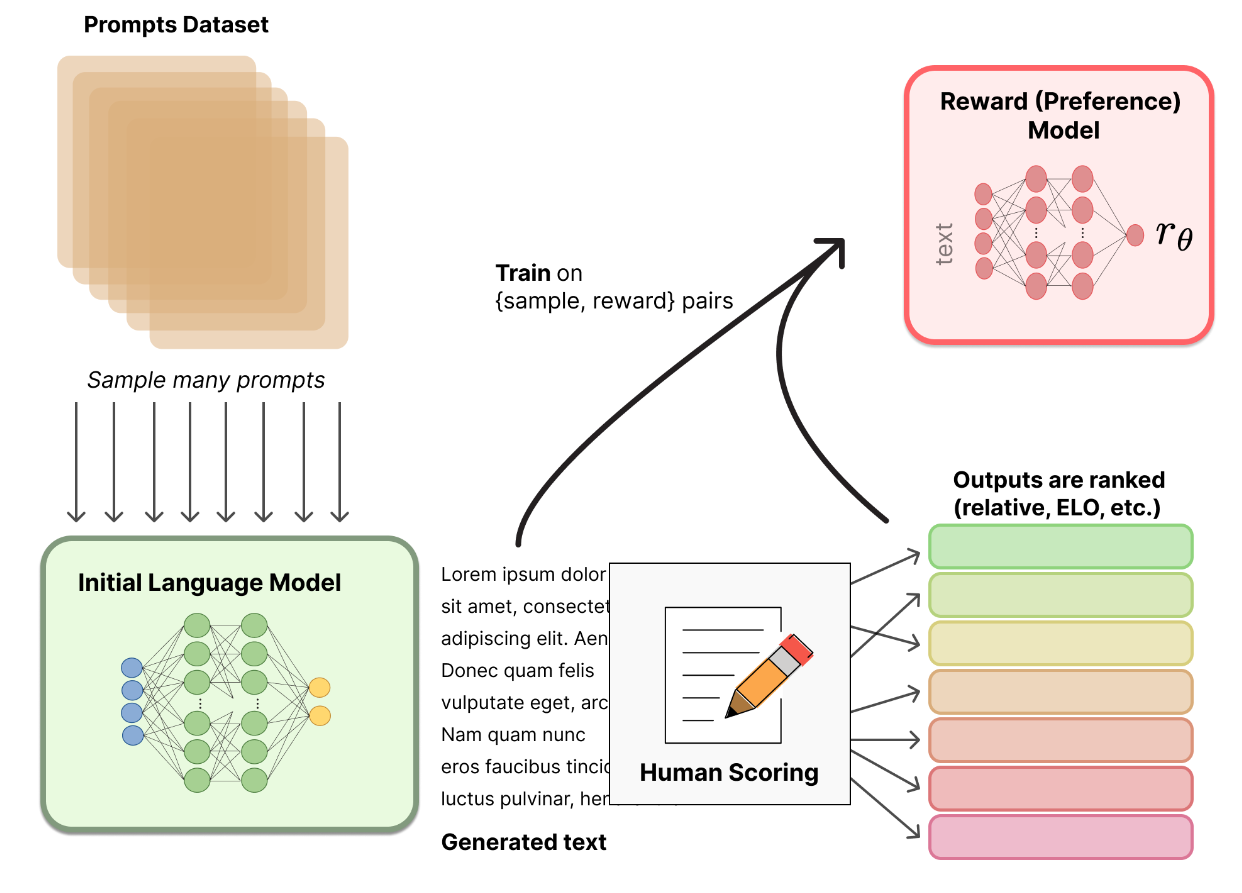
OpenAI에서는 1단계에서 준비한 SFT 모델을 약간 수정해
prompt와 그에 대한 response를 입력받아
scalar reward를 출력하는 RM을 만들었습니다.
대신 RM의 사이즈는 6B짜리를 사용했다고 논문에서는 밝히고 있습니다.
그 이유로 175B 짜리 RM은 안정적으로 훈련시키기가 어렵고,
3단계 RL과정에서 175B RM을 value function으로 썼을 때 적당하지 않았기 때문이라고 설명하고 있습니다.
(자세한 내용은 InstructGPT 논문 부록 C.2 Details of RM training 을 참고하세요.)
Anthropic에서는 Preference Model Pre-training (PMP) 라는 방식으로
RM에 쓸 Preference model을 새로 Pre-train 시킨 후
이 Preference model을 다시 fine-tuning하여 RM을 만들었습니다.
(구체적인 방법은 Athropic이 발표한 A General Language Assistant as a Laboratory for Alignment 논문의
4 Preference Model Pre-Training and Transfer 를 참고하세요.)
Anthropic의 RM의 사이즈는 LM과 같습니다.
RM의 핵심은 어떤 데이터를 어떻게 사용할 것인가라고 볼 수 있습니다.
OpenAI의 InstructGPT의 경우 인간이 직접 LM이 생성한 답변에 rank를 매겨 이 순위를 RM이 학습하도록 했습니다.
이 방식은 확실한 품질 확보가 가능하다는 장점이 있지만 비용이 매우 비싼 방법입니다.
Anthropic에서는 PMP를 위한 dataset을 웹페이지에서 샘플링하는 방식으로 구축했습니다.
예를 들어, StackExchange 웹사이트에서 질문에 대한 답변들을 수집한 후
각 질문의 모든 답변들에 대한 점수를 평가하는 공식을 만들었습니다.
점수는 가장 가까운 정수로 반올림된 log(1 + 답변의 upvotes수)로 정의되고,
질문자가 답변을 수락한 경우는 1을 더해줍니다. 반대로 upvotes수가 음수인 경우엔 -1점을 할당합니다.
이렇게 정량화된 답변들은 고품질과 저품질 답변쌍으로 묶입니다.
이러한 과정은 human annotator가 필요하지 않으므로 훨씬 많은 양의 데이터를 자동화하여 수집할 수 있는 장점이 있습니다.
Anthropicd에선 PMP를 훈련시키는데 위와 같은 방법으로 580만건의 답변쌍을 구축해 사용했습니다.
이 밖에도 복수의 LM이 생성해 낸 답변을 Elo rating system을 사용해 순위를 매기게 할 수도 있습니다.
RM을 설계하는 방식은 1단계에서 어떤 PLM을 설계하느냐처럼 활발히 연구되고 있는 주제입니다.
중요한 것은 이 RM이 3단계의 RL에서 보상함수로 작용하기 위해선
RM의 출력이 scalar로 정규화되어야 한다는 사실입니다.
3단계 : RL
불과 몇년 전만 하더라도 언어 모델을 강화학습 방식으로 재교육하는 것은
굉장히 어렵거나 불가능한 과제라고 여겨져 왔습니다.
그러나 앞서 언급한 Fine-Tuning Language Models from Human Preferences논문에서는
RL 알고리즘 중 하나인 PPO(Proximal Policy Optimization)를 사용해 LM을 fine-tuning할 수 있는 가능성을 보여주었습니다.
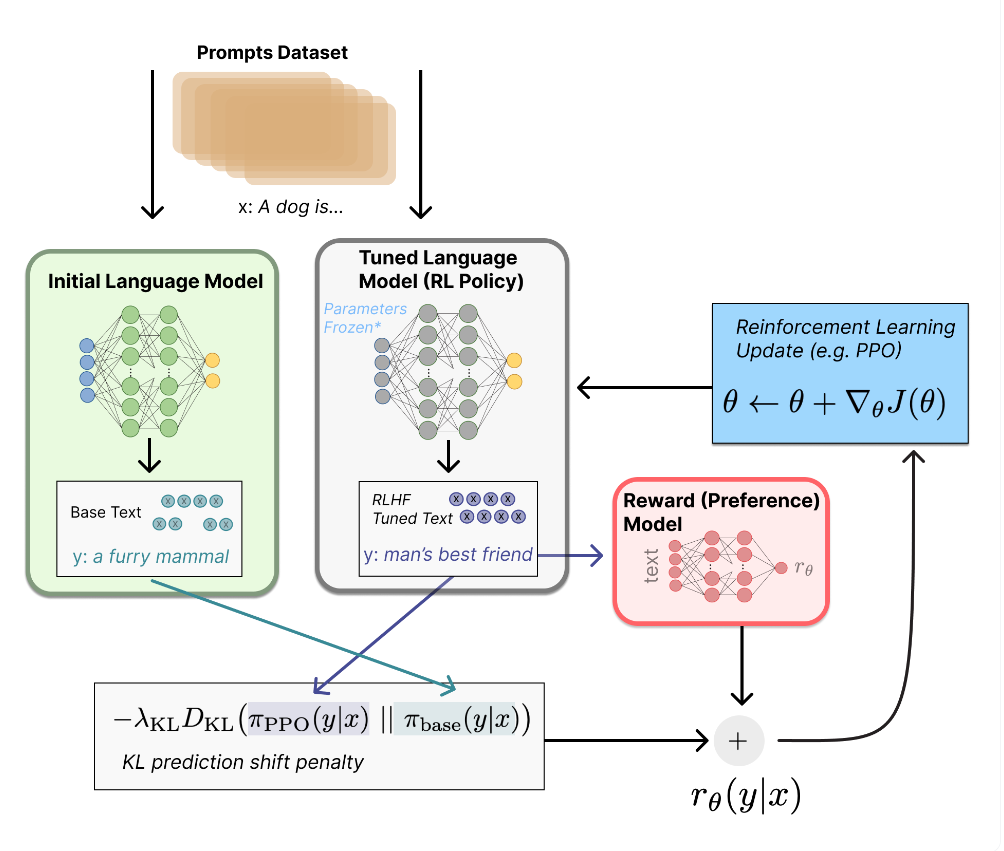
위 그림에서 회색 박스 안에 있는 Tuned Language Model이 RL과정에서 PPO로 학습될 모델입니다.
이 모델을 RL Policy라고 부르겠습니다.
RL policy는 1단계에서 만든 SFT model을 사용합니다.
연두색 박스 안에 있는 Initial Language Model은
RL Policy가 RM을 통해 업데이트될 때,
인간의 선호가 반영된 답변으로부터 너무 벗어난 문장을 생성하지 않게 제한을 걸어주는 페널티 역할을 합니다.
Initial model 역시 1단계에서 만든 SFT model을 사용합니다.
이와 같은 페널티가 없으면 RL Policy는 이상한 텍스트를 생성하기 쉬워지거나
반대로 RM으로부터 높은 보상을 받기 위해 RM을 속일 수도 있습니다.
페널티는 KL divergence를 활용해 RL Policy와 Initial model의 각 출력분포를 근사시키는 방법을 사용합니다.
따라서 위 그림에서 RL Policy가 입력받은 prompt에 대해 출력한 텍스트는
일단 RM으로 들어가고 (회색박스에서 붉은색 박스로의 화살표) RM은 보상을 출력합니다.
동시에 Initial model 역시 똑같은 prompt를 입력받아 텍스트를 출력합니다.
RL Policy와 Initial model의 각 출력으로 KL divergence값을 계산한 뒤
RM의 보상에서 빼준 값이 최종적인 보상이 됩니다.
만약 KL divergence값이 컸다면 (RL Policy가 Initial model과 너무 달라지게 된다면)
최종 보상의 크기가 줄어들게 되겠죠.
다시 말해 PPO로 업데이트 되는 RL Policy의 파라미터의 업데이트량에 페널티가 주어지게 되는 것입니다.
이제 InstructGPT의 RM에 사용되는 손실함수와 RL에 사용되는 목적함수는 각각 아래와 같이 수식화할 수 있습니다.

지금까지 RLHF를 구현하는 각 단계를 대략적으로 살펴보았습니다.
다음 노트에서는 LLM에 RLHF를 구현한 모델 코드를 통해
RLHF에 대한 이해를 더 높여보도록 하겠습니다.



