
questionet
LLM Trend Note (3) Emergent Abilities, Model scale과 Data size 본문
LLM Trend Note (3) Emergent Abilities, Model scale과 Data size
orthanc 2023. 6. 27. 13:421. Emergent Abilities의 정의
Emergence(창발)이란 철학과 과학에서 오랜 역사를 지닌 복잡한 개념입니다. (참고)
위키에서 볼 수 있듯이 창발에 대한 수많은 정의와 해석이 있지만
우리는 노벨물리학상 수상자인 Philip Anderson가 1972년에 발표한 에세이
"More Is Different" 에서 정의한 창발의 개념을 가지고 접근해보겠습니다.
"Emergence is when quantitative changes in a system result in qualitative changes in behavior."
번역하자면 "Emergence(창발)은 시스템에서의 양적변화가 질적변화를 가져올 때를 의미한다" 정도가 되겠네요.
우리는 앞선 노트에서
파라미터 스케일의 급진적인 변화가 가져온 모델 추론 능력의 질적인 변화의 예시들을 살펴보았습니다.
주요 LLM을 개발해온 Google과 Deepmind 그리고 유수 대학 연구자들은
2022년 10월 Emergent Abilities of Large Language Models 이라는 논문을 발표했습니다.
연구진은 LLM의 Emergent Abilities를 소규모 모델에는 없지만 대규모 모델에는 존재하는 능력으로 정의합니다.
따라서 Emergence는 모델 파라미터 수로 측정된 모델 규모와 관련지어 집니다.
아래 그림은 task별 모델의 성능과 모델 파라미터 개수 사이의 관계에서
Emergence가 나타나는 패턴을 보여주는 그래프입니다.
모두 단순한 few-shot prompting 에서의 Emergence를 나타냅니다.
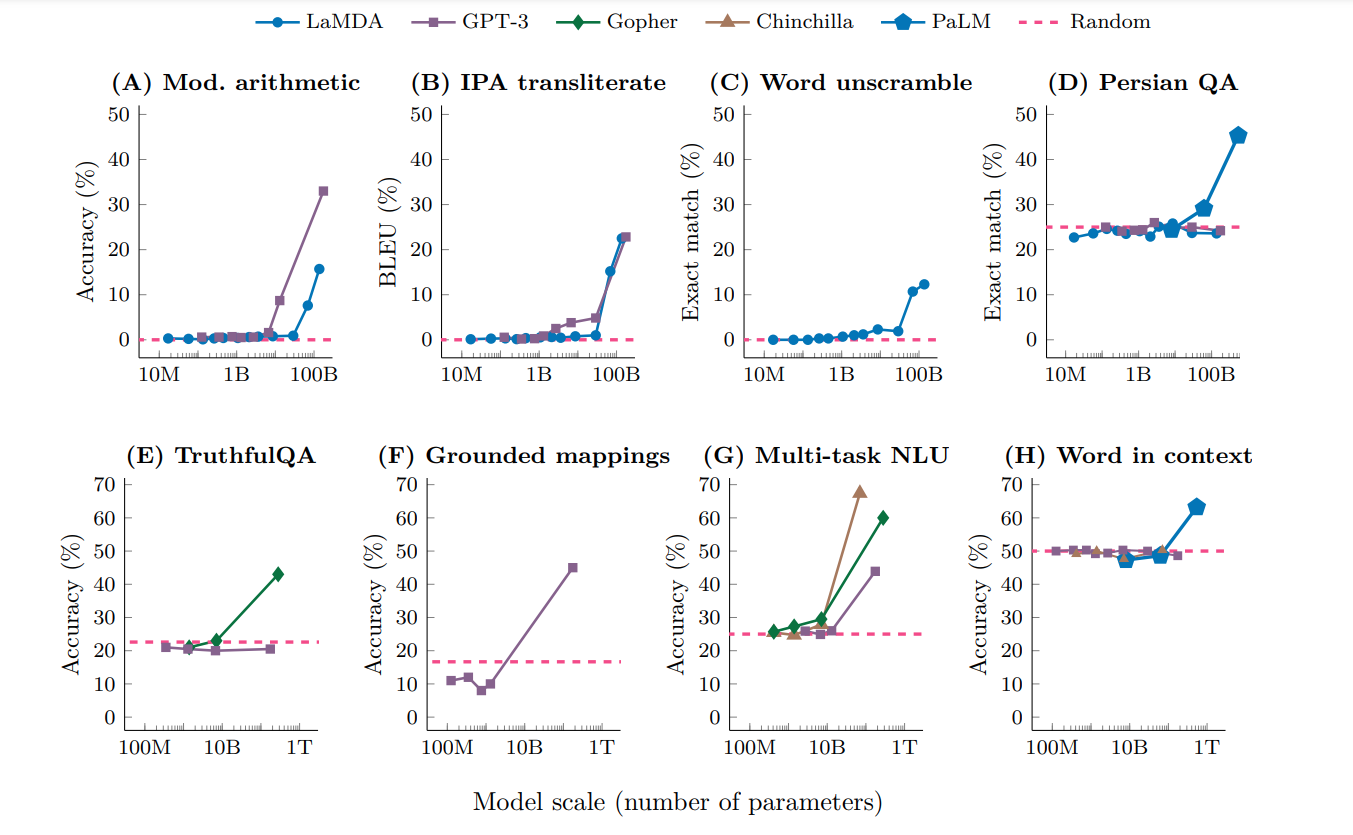
참고 : A, B, C, D 는 BIG-Bench, (출처 : https://github.com/google/BIG-bench)
E는 TruthfulQA benchmark,
F는 Grounded conceptual mappings,
G는 Massive Multi-task Language Understanding (MMLU) benchmark,
H는 (WiC) benchmark 입니다.
F에 관해선 논문 Mapping Language Models To Grounded Conceptual Spaces을 참고하세요.
모델 크기가 특정 임계값을 넘어서는 순간 모델 performance가 확연히 달라지는 걸 볼 수 있습니다.
우리는 이 패턴을 일종의 scailing law로 해석해볼 수 있습니다. 무어의 법칙처럼 말이죠.
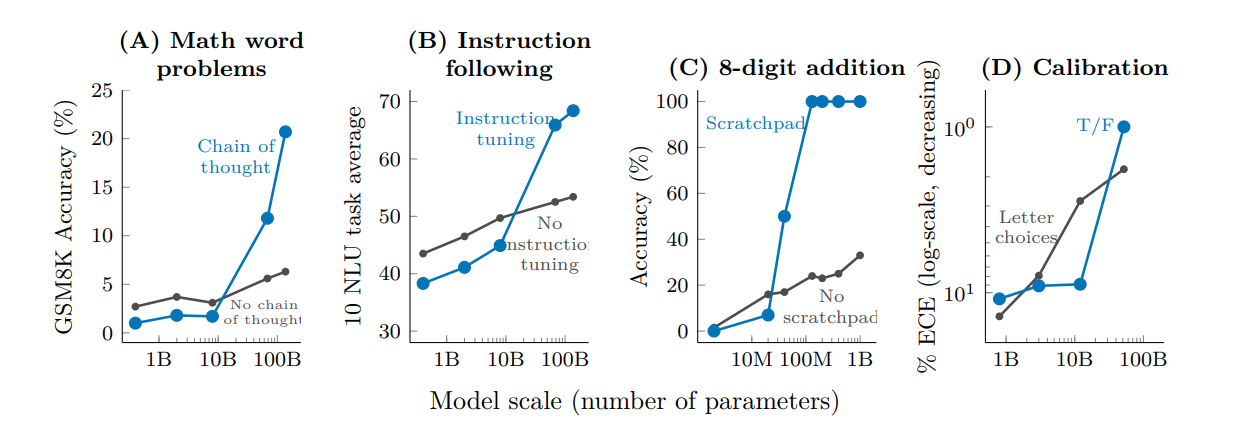
위 그림은 단순 few-shot prompting이 아니라 CoT 같은 좀더 고급의 prompt engineering을 사용하거나
instruction tuning 같은 고급의 fine-tuning 기법을 썼을 때 task별 performance의 Emergence 패턴을 나타낸 그림입니다.
참고 : A는 PaLM의 Chain of thought,
B는 FLAN의 instruction tuning,
C는 scratch pad 기법을 쓴 8자리 숫자 연산 task,
D는 model calibration 에서의 Emergence 입니다.
C와 D는 각각
논문 Show Your Work: Scratchpads For Intermediate Computation With Language Models과
논문 Language Models (Mostly) Know What They Know을 참고하세요.
앞서 살펴본 그래프와 마찬가지로,
모델 크기가 일정 수준을 넘어야만 해당 고급 기법들을 썼을 때 Emergent abilities가 나타나는 걸 볼 수 있습니다.
그림의 A와 B는 각각 앞선 노트에서 살펴본 PaLM의 CoT에 의한 Multi-step reasoning 능력과
Instruction following 능력에 해당됩니다.
C와 D도 위에 말씀드린 논문을 읽어보시길 권합니다.
2. LLM + Emergent Abilities = AGI?
Emergent Abilities에 관해 더 생각해볼 만한 문제들
여기까지 보면 LLM의 Emergent abilities 라는게 몇 개 되지 않아 보입니다.
하지만 Emergent abilities를 보이는 LLM들이 아직 human performance에 준하는 성능에 한참 미달하는,
다시 말해 잘 풀지 못하는 task들이 즐비하다는 사실을 간과해선 안됩니다.
Big Bench에는 GPT-3나 PaLM이 힘을 못쓰는 task들이 수십 개나 남아 있습니다.
몇가지만 예를 들어보면, anachronisms, formal fallacies syllogisms negation, mathematical induction 등등,
인간에게도 쉽지 않은 task들이지요.
Emergent Abilities가 정확히 무엇인지, 어떤 능력들이 Emergent Abilities에 포함될 수 있는지,
그것을 어떻게 발현해낼 수 있는지는 딥러닝 연구자들에게 있어 이제 막 시작된 최첨단 연구 주제 입니다.
BIG-bench만으로 상상가능한 모든 Emergent Abilities를 다 설명해낼 수 있을까요?
Emergent Abilities의 후보로 꼽히는 것들에는 수십여 가지나 있지만,
그러한 능력이 나타나는 방식에 대한 설득력 있는 설명은 거의 없습니다.
따라서 우리의 아래의 3가지 질문으로 사고를 확장해 볼 필요가 있습니다.
1.LLM의 pre-training obectives가 Emergent abilities에 영향을 미치는 것은 아닐까요?
이 질문에 대해 아래 논문을 참고해보세요.
What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
(출처 : https://arxiv.org/pdf/2204.05832.pdf)
보다 근본적으로 PLM이 왜 downstream task를 잘 수행할 수 있는 것일까?
라는 질문도 해볼 수 있을 것 같습니다.
이 질문에 대해선 아래 논문을 참고해보세요.
Why Do Pretrained Language Models Help in Downstream Tasks? An Analysis of Head and Prompt Tuning
(출처 : https://arxiv.org/pdf/2106.09226.pdf)
2.Emergent abilities를 어떻게 측정해야 할까요?
Emergence_model scale 그래프의 D~H benchmark들은 Multi-step reasoning 능력과 관계가 있습니다.
하지만 그래프에서 사용한 메트릭들은 모델이 추론해낸 최종답변에 대한 일치여부만 평가합니다.
앞선 노트의 chain of thought 그림에서 살펴보았듯이
다단계 추론의 과정을 답변에 포함해낼 수 있는 모델에게
추론의 결과 얻어지는 최종 답변의 T/F만 메트릭의 평가대상으로 사용할 경우,
모델이 추론과정에서 실수를 하거나 틀렸는지에 대해선 알 수 가 없습니다.
이런 가능성을 내포하고 있는 모델이
Emergent abilities를 가졌다고 한다면 선뜻 동의하기 어렵습니다.
즉, Emergent abilities는 그것을 지금 수준보다 더 정밀하고
섬세하게 평가할 수 있는 메트릭에 의해 규정되어야 합니다.
더 자세한 내용은 https://arxiv.org/pdf/2206.07682.pdf 논문의 부록 A를 참고하세요
3.Emergent abilities에는 긍정적인 능력만 포함되는 걸까요?
Emergent abilities에 위험한 능력이 포함될 수 있는 건 아닐까요?
LLM의 truthfulness, bias, and toxicity 에 관한 연구가 최근 들어 주목을 받고 있습니다.
사실과 구별되기 매우 힘든 거짓을 만들어 내거나,
비윤리적인 행위에 도움을 주는 결과물을 생산해내는 모델의 유해한 추론능력들은
역설적이게도 Emergent abilities가 확장됨에 따라 나란히 강화될 수 있습니다.
이 문제에 관심있으신 분들은
논문 On the Opportunities and Risks of Foundation Models 의
5절 society 부분을 참고하세요.
(출처 : https://arxiv.org/pdf/2108.07258.pdf)
위와 같은 리스크 때문에 HHH(Helpful, Honest, Harmless) 와 같은 기준이 모델에 요구되고 있습니다.
HHH 에 대해서는 Anthropic이 2022년에 발표한
논문 A General Language Assistant as a Laboratory for Alignment의
부록 E Definitions of Alignment and the HHH criteria 를 참고하세요.
(출처 : https://arxiv.org/pdf/2112.00861.pdf)
참고로 모델이 HHH 기준을 충족시키지 않는 문제를 alignment problem 이라고도 합니다.
그래서 InstructGPT의 RLHF technique을 alignment techniques이라고 부르기도 하지요.
이에 관해선 다음 노트에서 좀 더 자세히 다뤄보겠습니다.
이제는 AGI의 시대?
이처럼 LLM의 Emergent abilities에 관해 아직 해결되지 않은 문제들이 많음에도 불구하고,
모델 파라미터의 적극적인 스케일링을 통한 LLM의 확장은 한가지 중요한 시사점을 우리에게 던져주고 있습니다.
바로 훈련 데이터에 명시적으로 인코딩되지 않은 다양한 task를
단일 모델이 수행해낼 수 있는 수준까지 딥러닝 모델이 발전했다는 사실입니다.
Emergent Abilities를 "unseen task를 수행해내는 능력" 이라고 좁게 해석한다면,
우리가 지금까지 살펴본 LLM들을 "범용" 모델이라고 부를 수 있을 것 같습니다.
이로부터 촉발된 수많은 후속 연구들은 ASI(Artificial Super Intelligence)로 넘어가기 위해
반드시 넘어야 하는 AGI(Artificial General Intelligence)의 시대에 접어들었다고 볼 수 있을 법한 결과물들을 담아내고 있습니다.
관련하여 몇 가지 최신 연구결과물들을 소개해드리겠습니다.
1. Robotics and Virtual agent
우리가 prompt라는 이름으로 natural language instructions을 모델에게 주었을 때,
단순히 컴퓨터 모니터 상에서 Emergent abilities를 보여주는 데서 더 나아가
로봇이나 가상환경의 아바타가 우리의 instruction에 따라 행동할 수 있도록 하는 연구들이 진행되고 있습니다.
이와 관련한 대표적인 논문 2개를 소개합니다.
ㄱ. Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
ㄴ. Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents
2. Interact with users
우리가 입력한 대로만 결과물을 출력하는 모델이 아니라,
실시간으로 대화를 주고 받으며 작문을 도와주는 모델 에디터처럼
인간과 상호작용하며 결과물을 만들어내는 모델에 관한 연구도 진행되고 있습니다.
이와 관련한 Google Research의 대표적인 논문 3개를 소개합니다.
ㄱ. Wordcraft: a Human-AI Collaborative Editor for Story Writing
ㄴ. AI Chains: Transparent and Controllable Human-AI Interaction by Chaining Large Language Model Prompts
ㄷ. PromptChainer: Chaining Large Language Model Prompts through Visual Programming
3. Facilitate multi-modal reasoning
텍스트 데이터 뿐만 아니라, 비주얼 데이터 입출력도 가능한
이른바 시각적 언어모델 VLM (visual-language models)에 관한 연구도 있습니다.
이와 관련한 대표적인 논문 2개를 소개합니다.
ㄱ. Google의 Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
ㄴ. Deepmind의 Flamingo: a Visual Language Model for Few-Shot Learning
개인적으로는 제목부터 도발적인 논문 "Do As I Can, Not As I Say"이 가장 인상적인 연구가 아닐까 싶습니다.
LLM + Emergent Abilities = AGI?
우리는 지금까지 Emergent Abilities에 관해 더 생각해볼 만한 문제들과 후속 연구들까지 살펴봤습니다.
이제 다음과 같은 질문을 던져볼 차례입니다.
"더 많은 데이터를 더 큰 모델에 학습시키는 방법만이, Emergent abilities 를 확장할 수 있는 유일한 길일까?"
상대적으로 더 작은 LLM에서 더 놀라운 Emergence가 발견되었다는 보고가 여러 논문을 통해 발표되고 있습니다.
2022년, instruction tuning 방법을 소개한 FLAN 논문에서 쓴 모델은 LaMDA 137B였습니다.
상술했듯이 LaMDA는 디코더 기반 트랜스포머 모델입니다.
LaMDA는 pre-train시 2.49T 개의 토큰을 봤다고 합니다.
(FLAN 논문 2.4 Training Details 참고)
비슷한 시점에, 허깅페이스에서 발표한 T0 모델은
그보다 훨씬 적은 11B 개의 파라미터만 사용한 인코더-디코더 아키텍쳐의 트랜스포머 모델입니다.
하지만 T0가 pre-train시 학습한 토큰양은 1T에 달합니다.
모델 사이즈는 1/10 넘게 줄었지만 데이터 사이즈는 1/2 줄어든 것이죠.
그런데 T0는 baseline으로 사용했던 11B보다 더 적은 3B 사이즈의 동일 아키텍쳐의 모델로
FLAN보다 더 나은 성능을 냈다고 보고했습니다.
(논문 Multitask Prompted Training Enables Zero-Shot Task Generalization 참고)
Gopher와 Chinchilla는 2022년 전후로 Deepmind에서 발표한 LLM입니다.
Chinchilla 70B의 경우 Gopher 280B 의 1/4 수준 크기의 모델이지만 연산량은 비슷합니다.
(논문 부록C 참고)
Gopher 280B의 경우 pre-train시 325B 개의 토큰을 학습했지만
Chinchilla 70B는 1.4T 개의 토큰을 학습했다는 사실이 한 가지 주요한 원인이 될 수 있죠.
Chinchilla는 Gopher가 수행한 모든 downstream task에서 더 나은 performance를 냈습니다.
(참고로 Chinchilla는 Gopher의 모델 아키텍쳐를 거의 그대로 가져왔고
토크나이저와 옵티마이저, 연산단위 및 데이터셋 구성만 약간 바꿔 훈련시킨 모델입니다)
또다른 예로 PaLM 62B 모델은 GPT-3 175B 및 LaMDA 137B에 비해
1/3에서 1/2 수준으로 작은 사이즈의 모델임에도 불구하고
자연어 이해(NLU) 및 자연어 생성(NLG)에서 GPT-3보다 나은 성능을 냈습니다.
(PaLM 논문 Appendix H1 참고)
여기서 PaLM 62B와 GPT-3가 pre-train 시 사용한 토큰 총량은 각각 795B, 300B개 였습니다.
Data size가 Model size보다 더 중요할 수 있다는 사실을 지적한
Deepmind의 논문 Training Compute-Optimal Large Language Models 은
다른 관점의 scailing law를 제시합니다.
데이터를 추가할 때 얻을 수 있는 이득은 엄청난 반면,
모델 크기를 키웠을 때 이득은 미미하다는 것이죠.
아래 그림은 Chinchilla 논문의 주요 내용을 다룬 블로그에 있는 그래프 입니다.
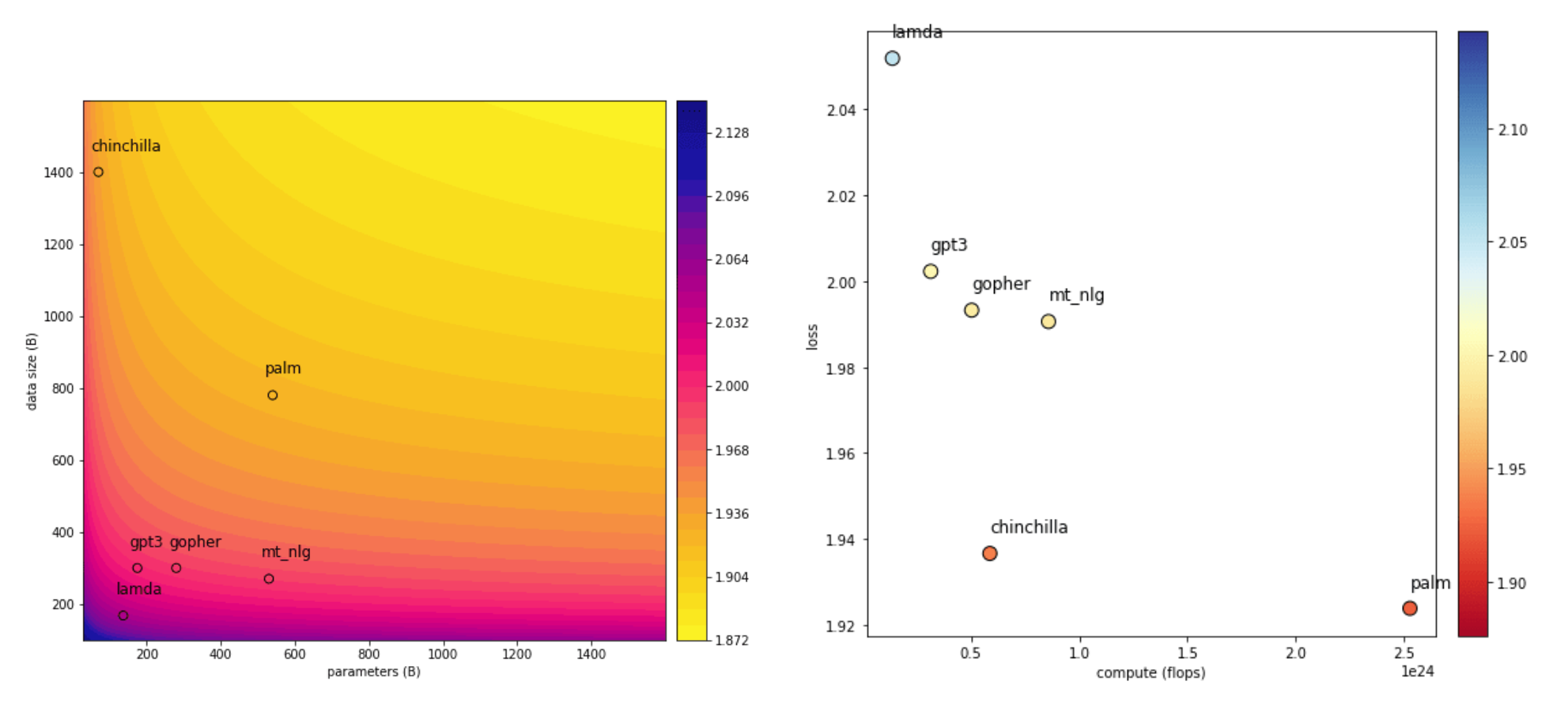
LLM과 Emergent abilities의 관계에 반드시 거대한 model scale이 요구되는 것은 아닙니다.
Chinchilla의 경우 더 작은 모델로 더 많은 데이터를 학습시켰을 때
학습 성능은 유지되면서 계산비용은 낮출 수 있음을 볼 수 있습니다.
인간의 지능을 구현하는 뇌 용량도 결국은 뉴런과 시냅스의 개수로 유한히 정해져 있습니다.
우리 대부분은 물리적으로 같은 뇌를 가지고 태어났지만,
어떤 정보를, 얼마나 많이, 어떻게 학습했느냐가 우리의 지능 수준을 더 좌우하는 것처럼 보입니다.
즉 모델 크기를 고정했을 땐, 데이터의 양뿐만 아니라 질도 큰 영향을 미칠 수 있다는 것일텐데
이러한 논리는 LLM에도 비슷하게 적용되는 것 같습니다.
고품질 데이터로 훈련된 모델일 경우 모델 파라미터가 더 적어져도 Emergence가 나타날 수 있을까요?
OpenAI에서 발표한 chatGPT의 전신인 InstructGPT는
GPT-3와 동일한 아키텍쳐를 베이스 모델로 하여
파라미터 스케일을 1.3B, 6B, 175B 세가지 버젼으로 달리해 구현한 모델입니다.
그 중 가장 작은 1.3B InstructGPT가 생성해낸 문장과
175B GPT-3가 생성해낸 문장을 두고 실제 인간의 선호도를 조사한 결과,
사람은 InstructGPT가 생성해낸 문장을 더 선호했습니다.
(논문 Training language models to follow instructions with human feedback 참고)
InstructGPT에서 눈여겨 봐야할 점은
1.3B 짜리 GPT 모델이 pre-train시 300B개의 토큰 밖에 보지 않았음에도(LaMDA와 Chinchilla, PaLM과 비교해보세요)
SOTA의 기준이었던 GPT-3보다 좋은 성능을 냈다는 사실입니다.
무엇이 이걸 가능하게 했을까요?
InstructGPT에서 사용한 학습메커니즘의 핵심은
LLM + RLHF(Reinforcement Learning Human Feedback)에 있다고 분석됩니다.
그리고 RLHF의 핵심 중 하나는 모델이 "데이터의 품질을 스스로 판별하여"
더 나은 결과물을 만들어낼 수 있게 하는 것입니다.
InstructGPT가 다른 LLM과 다른 점이 바로 여기에 있습니다.
이를 위해선,
첫째로 고품질 데이터와 저품질 데이터가 구분되어야 하고,
둘째로 그 구분을 스스로 학습해낼 수 있는 메커니즘이 필요했을 것입니다.
즉, 모델 스케일이나 데이터의 절대적인 크기가 Emergent Abilities의 전부가 아니라,
어떤 데이터를 어떻게 학습시켰느냐 라는 문제의식이 여전히 강력하게 유효하다는 걸 여실히 보여준다고 말할 수 있습니다.
InstructGPT가 RLHF를 할 때 사용한 데이터는 11만 건 정도밖에 되지 않습니다.
(InstructGPT 논문 Appendix A.3 Dataset sizes 참고)
물론 모델 사이즈와 관련해서,
"현재 수준의 모델 사이즈는 앞으로도 필요할 것이다" 내지
"앞으로 모델 사이즈는 더 커져야 할 것이다" 라는 의견이 있을 수 있습니다.
이러한 직관은 일견 일리가 있어 보입니다.
예를 들어, 앞서 살펴본 Multi-step reasoning 능력의 경우,
n단계의 순차적 추론이 필요한 경우 최소 O(n) 레이어의 깊이가 있는 모델이 필요할 수 있습니다.
commonsense reasoning 처럼 우리가 살고 있는 세계에 대한 상식에 관한 추론의 경우,
인간에게도 일정 수준 이상의 암기력은 필요하고
모델 역시 일정 수준 이상의 레이어는 최소요건으로 충족시켜야 한다고 볼 수 있을테니까요.
하지만 위 질문에 대한 답은 현재 굉장히 논쟁적인 사안입니다.
확실히 우리는 모델이 얼마나 더 커질 수 있고, 그렇게 거대한 모델이 어떤 능력을 가질 수 있을지 그 끝을 보지 못했습니다.
조금 더 조심스럽게 접근하자면
LLM의 Emergent abilities는 위에서 살펴본 요소들 외에
아직까지 발견되지 않은 미지의 요소로 나타난다고 가정할 수도 있습니다.
완전히 최적화된 훈련방법이란 무엇인지,
최신 학습기법들로 학습시켰을 때 그 기법들이 최선의 학습기법이 맞는지는
시간에 따라 재해석 될 수 있기 때문입니다.
더 나아가 Deep learning model의 interpretability 문제도 영향을 미칠 수 있습니다.
그러나 지금까지 살펴본 모든 LLM들의 기본 아키텍쳐인 트랜스포머도,
더 긴 시퀀스를 더 효과적으로 처리해 낼 수 있는 셀프 어텐션 아키텍쳐에 대한 고민이 없었다면 탄생할 수 없었습니다.
PaLM과 같은 초거대 모델을 학습시키는 데에는,
대량의 데이터나 모델 파라미터를 키우는 아키텍쳐보다
분산컴퓨팅을 위한 AI backend Engineering 기술에 대한 고민이 선행되어야 합니다.
무엇보다도, 소수 연구자와 기술자의 전유물이 아닌
더 많은 사람들이 기술발전의 혜택을 누릴 수 있도록 모델 사이즈를 더 줄이면서도 비슷한 성능을 낼 수 있으면서,
대중 일반이 사용할 수 있는 컴퓨팅 환경에서 실행가능한 학습 테크닉을 개발하고자 하는 고민에서 비롯된
목소리와 움직임들이 있습니다.
한편으론 이런 고민과 시도들이 우리 인간이 가진 Emergent abilities가 아닌가 하는 생각이 듭니다.
이런 고민과 시도까지 해낼 수 있는 인공지능이라면 AGI라는 이름을 붙여도 되지 않을까 조심스레 생각해봅니다.
다행히(?)도 OpenAI에서 ChatGPT를 AGI의 효시로 내걸어주었습니다.
(Planning for AGI and beyond 참고)
OpenAI의 말대로 ChatGPT를 통해 우리가 AGI에 점점 다가가고 있는 것이라면,
지금까지 살펴본 수많은 LLM중 ChatGPT에 대해 좀 더 자세히 알아볼 필요가 있지 않을까요?
그럼 이어지는 다음 노트에서 ChatGPT의 핵심 기술인 RLHF에 대해 좀 더 자세히 살펴보도록 하겠습니다.



