
questionet
신경망 학습 (경사하강법) 본문
이 페이지는 밑바닥부터 시작하는 딥러닝1권의 내용을 정리한 것이다
살펴볼 대주제 : 손실함수와 수치미분 그리고 편미분
곁들일 소주제 : 몇 가지 질문과 미니 배치
1. 손실함수
들어가며
1. 눈으로 보는 이미지, 귀로 듣는 소리, 언어로 표현되는 문장, 각종 수치들(날씨 정보, 주가 등등)
2. 다양한 형태의 데이터들을 ----> 숫자로 변환 (입력값)
3. 신경망에 데이터(입력값)들을 넣어서 분류 또는 예측 >>>> 딥러닝을 사용해 하는 일들
4. 어떻게 분류, 예측을 할까?
데이터 주도 학습 ( data-driven approach )
1. 데이터에서 가장 본질적인 특징(feature)을 추출한 다음 ----> 패턴을 학습시키자!
2. 특징을 사람이 선별해서 알려주는 게 아니라 ----> 신경망이 스스로 찾아내게 하자!
신경망이 데이터에서 어떻게 특징을 찾아내게 할까?
가중치 매개변수 ( Weight parameter )
1. 입력값 하나 하나에 대응하는 W를 임의로 부여 (가중치 초기화)
2. 활성화 함수를 통해 출력값을 산출
activation function ( Sigmoid / Relu )
y = h ( Wx + b )
h(x) = 0 ( x<=0) or h(x) = 1 ( x >0)
3. 데이터의 특징을 가장 잘 표현하는 가중치를 찾아낸다면 ----> 0 과 1 중 우리가 원하는 답을 내어줄 수 있다!
데이터의 특징을 가장 잘 표현한다는 걸 어떻게 알 수 있을까?
손실함수 (loss function = 비용 함수 cost function )
1. 손실함수는 최적의 매개변수(가중치와 편향 값)을 찾는 과정에서 사용.
최적의 가중치 매개변수란 데이터의 특징을 가장 잘 표현하는 W값
1 부터 10 까지 쓰여진 숫자 이미지를 분류하는 문제를 생각해보면,
10개의 숫자 중 하나의 숫자 이미지 픽셀 값들을 입력으로 받아 신경망이 추정한 값들에서
[신경망의 은닉층 = 활성화 함수와 출력층 = 출력함수 (항등함수, 소프트맥스 함수)를 거쳐 나온 출력값]
y = [ 0.1 , 0.05 , 0.6 , 0.0 , 0.05 , 0.1 , 0.0 , 0.1 , 0.0 , 0.0 ]
정답레이블 ( 0 또는 1 ) 을 각각 빼준 값들을
t = [ 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ] <<< one-hot encoding
제곱하여 모두 합한 결과가 가장 작으면 신경망 추론의 정확도가 높다고 말할 수 있다.
Q : 이게 무슨 말인가?
A : 0부터 9까지 10개의 숫자를 순서대로 가리키는 레이블인 t 배열에서
세번째 레이블만 1이고 나머지는 0이라는 것은
입력된 이미지의 정답이 숫자 2 라고 신경망이 말하고 있는 것이다.
하지만 신경망은 자기한테 입력된 숫자가 뭔지 모른다. 다만,
신경망이 추정한 세번째 y값 0.6이 입력 이미지의 가장 본질적인 특징을 나타내는 w가 반영된 결과값이라면
결과적으로 신경망은 숫자 2 이미지가 가진 본질적인 특징(최적의 W값)을 찾아낸 것이다.
이는 오차제곱합에 위의 수치들을 대입해 보아도 알 수 있다.
레이블 10개 중 하나만 1이고 나머진 모두 0이므로
오차제곱합의 정의에 따라
결국 신경망이 추론한 값중 가장 높은 값에서 1이 빼어져야
손실함수의 값은 가장 낮아지게 된다.
이는 동시에 신경망의 추론이 아주 신뢰할 만하다는 걸 의미한다.
위와 같은 방법을 오차제곱합 ( sum of squares for error, SEE) 이라고 부른다!
0.5 * np.sum ( ( y - t ) **2 ) <첫 번째 손실함수>
Q : 이미지의 픽셀 총 개수는 작게는 수백 많게는 수천 수만개가 될텐데
이 입력값들이 어떻게 마지막에 10개의 숫자로 줄어들 수 있을까?
A : 벡터, 선형대수, 신경망의 깊이
Q : 왜 빼고 제곱하는 복잡한 과정을 쓰는 걸까?
A1: 제곱을 안하고 더하면 빼기한 결과가 음수일 경우 합이 바뀌므로
A2: 다항식을 전개하면 2차 함수가 되어 포물선 형태의 그래프를 얻을 수 있다
Q : 최적의 매개변수를 찾아낸다는 것의 의미는 이제 알겠다.
그럼 그 W를 신경망이 스스로 찾아낸다는 건 어떻게 가능해지는가?
경사하강법 Gradient Descent
W = W - a * (dL / dW )
손실함수를 W에 대해 미분한 값 ( dL / dW ) 을 처음 W 값에서 빼준 다음
그 결과를 새로운 W로 사용 ----> 이 과정을 반복
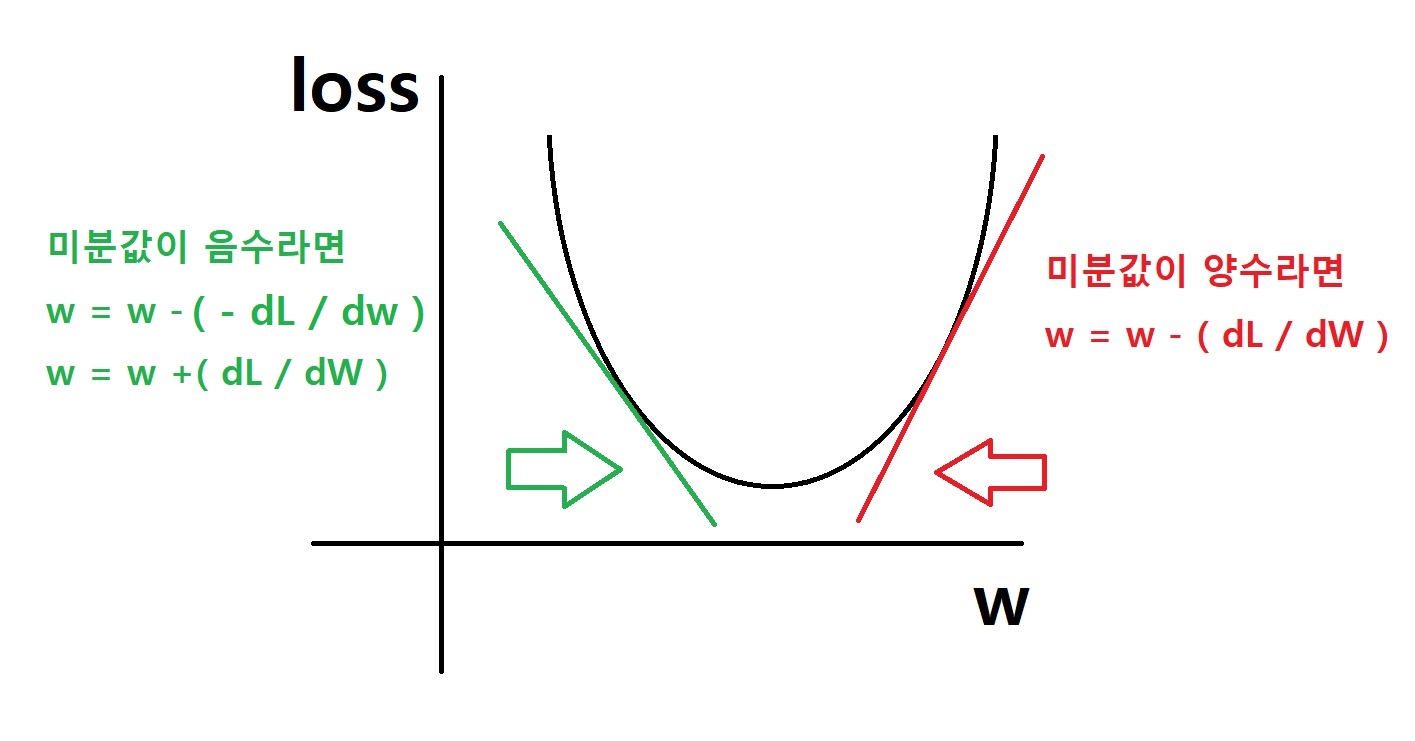
미분 값이 0이 되면 (즉 기울기가 0이 되면) 그 때의 손실 함수 값 loss 는 가장 낮아진다
"미분 값을 단서로 매개변수의 값을 서서히 갱신하는 과정"
이것이 바로 데이터의 가장 본질적인 특징(최적의 매개변수)를 신경망이 스스로 찾아내는 메커니즘의 하나
Q 또 다른 메커니즘들은 무엇인가?
A1 역전파 (Back propagation)
A2 다양한 모델의 종류들이 가진 고유한 작동원리들 ( CNN, RNN... )
두 번째 손실 함수, 교차 엔트로피 오차 ( cross entropy error, CEE )
delta = 1e-7
- np.sum ( t * np . log ( y + delta ) )
여기서 log는 밑이 e인 자연로그
식을 살펴 보면,
np . log ( y + delta ), 이 값에 정답 레이블 t를 곱해주는 데
정답 레이블은 0 또는 1이므로 ----> 정답, 즉 1일 때의 신경망의 추정한 값의 자연로그를 계산하는 식이 된다.
( 정답 레이블이 0인 경우엔 t 가 0 이므로
신경망이 추정한 결과값에 0을 곱하게 되니까 정답 레이블이 1인 경우만 보면 된다)
이것도 예를 들어 살펴보자
위에서 살펴본 이미지 분류 문제를 예로 들면,
신경망의 출력값 y = [ 0.1 , 0.05 , 0.6 , 0.0 , 0.05 , 0.1 , 0.0 , 0.1 , 0.0 , 0.0 ]
정답 레이블 t = [ 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ]
신경망의 출력이 0.6일 때 교차엔트로피 오차 값은 -log0.6 즉 0.51이 된다.
이는 곧 어떤 하나의 이미지를 넣었을 때 손실함수가 돌려주는 값이 0.51이라는 것이다.
Q : 여기서 어떤 하나의 이미지를 넣었을 때 얻게 되는 값이 0.51이라는 건 무엇을 의미하는 건가?
A : 자연로그 y = log x (밑 e는 생략) 의 그래프를 살펴 보자.
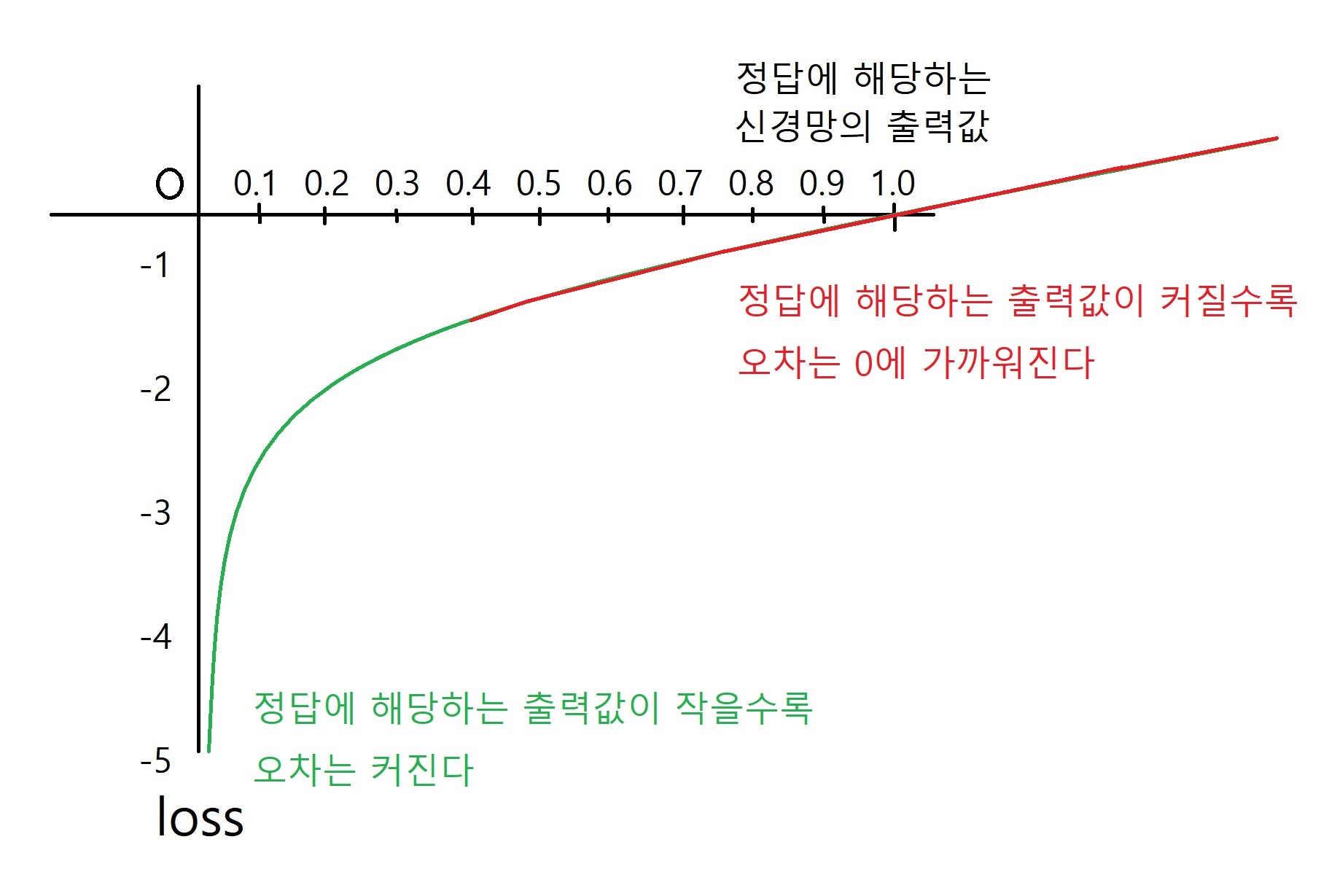
- np.sum ( t * np . log ( y + delta ) ) 수식의 맨 앞에 -를 붙였으므로
마이너스가 붙기 전엔 -0.51 일 것이다.
이 수치가 0에 가깝다고 본다면, 오차는 0에 가깝다고 해석할 수 있는 것이다.
만약 더 최적화된 W값을 찾아낼 수 있다면 수치는 0.51보다 더 작게 나올 것이다.
Q : 왜 자연로그를 사용해 함수를 만들었을까요?
A : 딥러닝에서 사용하는 활성화 함수인 sigmoid함수의 경우,
그 결과 값은 0에서 1사이로 떨어지게 된다
이 값에 자연로그를 취하면 위의 자연로그 그래프를 통해 알 수 있듯이
loss 값을 0 에서 무한대의 범위로 얻어낼 수 있기 때문이다.
활성화 함수로 Relu 함수를 쓰게 될 경우,
신경망의 출력값이 아주 큰 값이 나오게 되었을 때밑을 e로 하는 지수함수의 로그로 간주할 수 있기 때문에
결과값을 작게 바꿔 줄 수 있는 효과를 볼 수 있다.
Q : 수식 맨 앞에 마이너스는 왜 붙였을까요?
A : 그냥 자연로그 값을 계산하면 음수가 되므로 오차를 양수로 표현하기 위해 마이너스를 붙인다.
Q : log ( y + delta ) 델타는 왜 더해줬나요?
A : np.log() 함수에 0을 입력하면 마이너스 무한대 값이 나오므로
계산이 막히는 걸 방지하기 위해 아주 작은 값을 더해준다
교차 엔트로피 오차를 손실함수로 썼을 때에도 위와 같이 비선형의 그래프가 그려지므로
오차제곱합 손실함수에서처럼 경사하강법을 쓸 수 있다!
그럼 경사하강법의 핵심인 미분에 대해 좀 더 알아보자!!
2. 수치미분
1. 미분이란?
이런 함수에서의 미분이란 거칠게 말해서 x를 아주 아주 조금 변화시켰을 때
y의 값이 얼마나 변하는지를 구하는 작업
그런데 아주 아주 작은 값은 0.00000000000000001 처럼 끝도 없이 나열할 수 있다
우리가 '이 정도면 충분히 작은 값이다' 라고 어떤 매우 작은 값 h를 임의로 정한 다음
h = 1e-4 (h = 0.0001)
(( f ( x + h ) - f (x )) / h
위의 식에 넣어 구하는 미분을 수치 미분 (numerical differentiation) 이라고 한다
(전방 차분 forward differencing 이라고도 한다. 이렇게 부르는 아래 그래프 참고)
2. 수치 미분의 문제점
ㄱ. 만약 h에 너무 작은 값을 넣으면 컴퓨터는 올바로 표현할 수 없다
Q : 왜?
A : 부동소수점 방식으로 실수를 표현하는 컴퓨터는 너무 작은 값을 입력하면 반올림 오차를 일으킨다
Q : 부동소수점 방식이란? 그 결과 생기는 반올림 오차의 문제란?
A : 실수를 컴퓨터상에 근사하여 표현할 때 소수점의 위치를 고정하지 않고
그 위치를 나타내는 수를 따로 적는 것
부동소수점으로 표현하게 되면 실수를 정확히 표현하지 못하고,
실제 수학적 연산 역시 정확히 표현하지 못하는 부작용이 있다
참고 자료 ko.wikipedia.org/wiki/%EB%B6%80%EB%8F%99%EC%86%8C%EC%88%98%EC%A0%90
ㄴ. 수치 미분은 임의의 아주 작은 값을 넣었기 때문에 그보다 더 작은 h를 넣었을 때 값과 비교하면 오차가 생긴다
3. 해결 방법
ㄱ. h 값으로 0.0001 을 사용하면 반올림 오차 문제를 피하면서 적당히 좋은 결과를 얻을 수 있다고 알려져 있다.
ㄴ. 중앙차분 (중심차분) 방법을 사용하면 수치미분을 사용함으로써 생기는 오차를 줄일 수 있다.
수치미분의 활용법 참고 영상 : https://www.youtube.com/watch?v=aIuOHX2ksAg
4. 중앙차분이란?
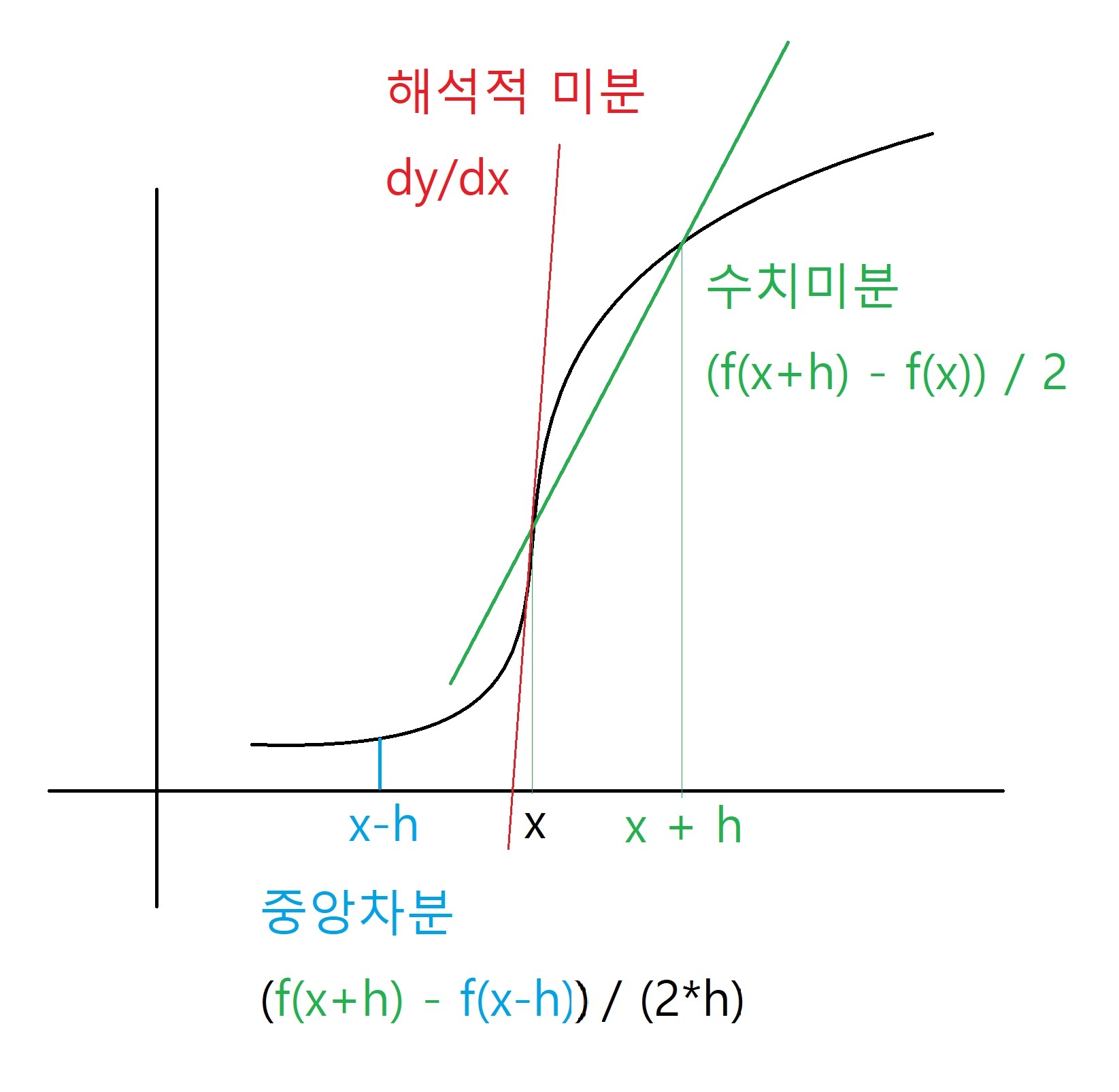
x를 중심으로 그 전후의 h를 고려해 함수 f의 차분을 계산
3. 편미분 partial derivative
1. 편미분이란?
함수의 변수가 x 하나만 있는 게 아니라
x, y 등 변수가 여러 개 있을 때 미분을 하는 방법

(여기서 편미분 기호를 델del, 디 dee, 편디partial dee, 파셜partial 이라고 부른다.)
예를 들어 각 변수 x , z에 대해 두 변수를 곱하는 다음과 같은 함수가 있을 수 있다.
ex ) f( x, z ) = xz
이 함수를 미분하기 위해서는 변수가 하나인 미분과 마찬가지로
미분하고자 하는 하나의 변수에 초점을 맞추고 다른 변수는 상수로 간주한다.
따라서 위 함수를 미분한다면 도함수의 공식에 따라서 x는 1이 되어서 미분값은 z가 된다.
(마치 f(x) = 3x 를 미분하면 3이 되는 것처럼)
컴퓨터로 편미분을 계산할 때는 수치 미분 코드를 써서 계산한다.
그러면 (( f ( x + h ) - f (x )) / h 수식에 따라
(3(x+h) - 3x) / h 를 계산하면 된다.
미분 참고서적 : book.naver.com/bookdb/book_detail.nhn?bid=15260256
2. 편미분은 어디에 사용하지?
예를 들어 f( x, z ) = x**2 + z**2
위와 같은 함수가 있다고 할 때
변수 x, z에 대해 함수값 f (x, z)가 생기므로
총 3가지의 수 x, z, f(x,z) 를 3차원 축에 하나의 공간형태로 그려볼 수 있다.
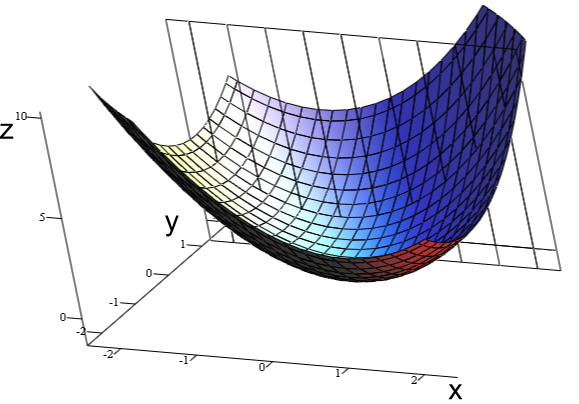
위의 그림처럼 엎어진 밥그릇 모양의 오목한 함수 convex function이라고 한다.
실제로 f( x, z ) = x**2 + z**2 와 같은 함수는 위의 그림에 나타난 곡면과 비슷한 형태를 갖는다.
딥러닝에서는 아주 많은 입력값과 그에 따른 가중치 매개변수들 그리고 다양한 함수들을 사용하기 때문에
고차원의 공간에서 경사하강법을 적용하기 위해 편미분을 해야한다.
Q : 잘 와닿지 않는데, 더 정확히 설명해줄 수 있나?
A : ............ 좀 더 공부해보고..
cf) 오차역전파법에서는 합성함수의 미분을 다룬다고 한다
수치미분으로 편미분하는 방법을 한 번 더 살펴보자.
예를 들어 f( x, z ) = x**2 + z**2 에서
x는 3이고, z는 4일 때
신경망에게 x에 대한 편미분을 하게 한다고 하면
x**2 + 16 을 수치미분한 것과 같다.
따라서
(( x + h )**2 +16)- x**2+16)) / h 에 x 는 3, h = 0.0001을 대입한 결과가
편미분 값이 된다.
4. 몇 가지 질문들
Q : "좋아, 손실함수를 쓰는 이유는 알겠는데 그냥 간단하게 신경망이 제일 예측을 잘한 값이나,
높은 확률 값을 가지고 정확도를 표현하면 안돼?"
A : 답정너. 경사하강법(미분)이라는 방법을 선택한 이상
정확도를 지표로 삼으면 그냥 상수를 미분하는 꼴이나 마찬가지.
Q : 수치미분말고 종이에 직접 수식을 써서 미분을 계산하는 방식을 컴퓨터가 하게 할 순 없나?
A : x의 최고차항이 n제곱일 때 함수 f 를 f(x) = ax**n 이라고 했을 때
이 함수의 미분df / dx는
도함수 공식에 따라 anx**n-1 로 계산한다.
이 미분법을 수치미분 (numerical) 과 대비해 해석적 미분 (analytic differentiation) 이라고 한다.
컴퓨터는 극한의 개념을 다룰 수가 없다. (극한은 인간 정신이 만들어 낸 추상적인 개념이므로)
따라서 해석적 미분을 할 수 없다.
인간이 직접 구한 미분의 해를 코드에 넣어서 사용한다.
5. 미니배치
앞서 살펴본 오차제곱합과 교차 엔트로피 손실함수 코드들은
0.5 * np.sum ( ( y - t ) **2 )
delta = 1e-7
- np.sum ( t * np . log ( y + delta ) )
하나의 데이터에 대한 손실함수다.
N 개의 데이터가 있다면 손실함수 N개의 모두 더해 그 평균을 내어서 평균 손실함수를 구하게 된다.
딥러닝은 매우 많은 수의 데이터를 훈련시킨다.
이 모든 데이터를 대상으로 손실함수를 하려면 시간이 걸린다.
이런 경우 데이터의 일부를 추려서 전체 데이터의 근사치로 사용하는 방법을 적용해 볼 수 있다.
미니배치 학습 이란 전체 훈련 데이터의 일부를 무작위로 골라 학습을 시키는 걸 말한다.
>>> 밑바닥부터 시작하는 딥러닝 책에서 말하는 미니배치학습은
우리가 배치학습이라는 의미에서 미니배치학습이라고 쓰는 용어와 조금 다른 것 같다.
전체 데이터 N개를 하나의 배치로 묶어 한번에 메모리에 올리거나 (배치학습)
전체 데이터 N개를 m개의 묶음으로 나눠 여러번 메모리에 올리는 (미니배치학습)
뜻에서의 미니배치가 아니라 전체 데이터에서 일부를 무작위로 추출해 학습시키는
일종의 통계적 방법으로서의 학습법을 말하는 것 같다.
'Deep learning > 딥러닝 학습기법' 카테고리의 다른 글
| delve into LoRA # 로라 파헤치기 (1) (0) | 2023.11.11 |
|---|---|
| word2vec (0) | 2021.02.08 |
| Backpropagation 요약 (sigmoid 함수와 tanh 함수의 미분) (2) | 2021.02.02 |
| Backpropagation 설명 (역전파) (0) | 2021.01.31 |
| Optimization (최적화 기법) (0) | 2021.01.17 |



