
questionet
Recurrent Neural Network (RNN) 본문
이 페이지는 밑바닥부터 시작하는 딥러닝2권과 다음 강의를 정리, 부연한 것이다
www.youtube.com/watch?v=dUzLD91Sj-o&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r&index=12
www.youtube.com/watch?v=qkb4WoonjeI
Feedforward Neural Network 와 Recurrent Neural Network 비교

Feedforward Neural Network에서
Image classification은 sequential data를 다루지 않는다. (입력에서든 출력에서든)
바꿔 말해 개별 이미지들은 한방에 처리된다. (대표적으로 CNN)
그런데 Recurent Neural Network에서는
Image classification이나 Image generation에서 입력되고 출력되는 non-sequential data인 image를
sequential processing 할 수도 있다.
예를 들어,
한 이미지 안의 여러 다른 부분들을 sequential하게 입력 받아, 해당 전체 이미지가 무엇인지 classification 한다든가
매 시점마다 캔버스의 여러 다른 부분들을 색칠해, 전체 이미지를 generate 하는 것이 가능하다.
글과 이미지를 인식하는 관점에서 보면 확실히
둘은 sequential VS non-sequential한 특징이 대조되는 데이터처럼 여겨진다.
책을 펼쳤을 때 보이는 문장 뭉텅이들을 인식할 때와
고개를 들어 창문 밖을 바라보았을 때 보이는 아파트 건물이 인식될 때
내 머리 속에 무언가가 인지되는(좀 더 구체적이고 확실한 의미를 주는) 것은
확실히 이미지 쪽이다.
하지만 여기에 어떤 트릭이 있는 것 같기도 하다.
"창문 밖으로 보이는 아파트 건물 한채를 보고 있다"
와
"책 한쪽에 가득 써있는 단어, 문장 덩어리들을 보고 있다"
에는
굉장한 정보의 비대칭성이 고려되어야 한다.
우리는 정당한 비교를 위해
'아파트를 찍은 이미지'와 '아파트라고 쓰인 단어'를 비교해야한다.
바꿔 말하면 이미지가 반드시 non-sequentia data인 것은 아니다.
예컨대 '텅빈 배경에 아기가 찍힌 사진'과
'현수막과 풍선이 걸린 천정 아래 수십명의 사람들이 둥글게 모여 저마다 어떤 행동들을 하는 가운데에 돌잡이를 하는
아기가 찍힌 사진'은
전혀 다르다.
마찬가지로 사진이 아닌 비디오라고 해서 반드시 sequential한 것도 아니다.
여기까지 오면
sequence라는 것은 '의미'가 있든 없든 순서대로 나열된 것이란 정의가 들먹여진다.
문제는 이 정의가
위의 Feedforward Neural Network 와 Recurrent Neural Network 비교 설명에선
그다지 엄밀하게 쓰이지 않고 있다는 것이다.
CNN에서 윈도우가 이미지를 일정한 방향으로 훑고 내려오는 것을
non-sequential 하지 않은 data를 sequential하게 처리하는 것처럼 이해하는 게 잘못된걸까?
위 설명에서 말하는 non-sequential한 이미지라는 것이 그저 숫자 하나가 달랑 찍힌 사진을 의미하는 것이라면
그걸 RNN으로 처리하는 게 그리 대수로워 보이진 않는다.
RNN의 기본 formular

Vanilla RNN의 정의

Vanilla RNN의 계산 그래프 예시

모든 RNN 계층에 똑같은 weight matrix를 사용함으로써 생기는 특징
1. 역전파시 기울기를 갱신할 때, 매 출력에 대한 기울기들을 다 더해주기만 하면 된다
(다른 표현으로 Repeat node(분기노드), Copy gate 라고도 한다)
Copy gate 참고 questionet.tistory.com/18?category=955972
cf) Sum node의 역전파는 Repeat node의 순전파와 같고
Repeat node의 순전파는 Sum 노드의 역전파와 같다.


2. 어떤 길이의 sequence data가 입력된다하더라도 다 처리할 수 있다.
길이가 2면 RNN계층을 두번 돌리면 되고, 길이가 100이면 100번 돌리면 되니까.
seq2seq 계산그래프 예시

Encoder의 weight matrix(W1)과 Decoder의 weight matrix(W2)는 다르다.
그런데 Encoder와 Decoder에서 똑같은 weight matrix를 쓰는 경우도 있다. 언제?
Vanilla RNN 으로 문자를 예측하는 모델을 예로 들어 구체적으로 살펴보자.
1. 먼저 foward pass는 다음과 같다

1. 여기서 hidden state Ht의 Weight matrix는 4 X 3
input Xt의 Weight matrix도 4 X 3 이어야 함을 알아야 한다.
2. 또한 각 시점의 입력의 결과 예측되는 값들은 다음과 같은 process를 거친다는 걸 알아야 한다.
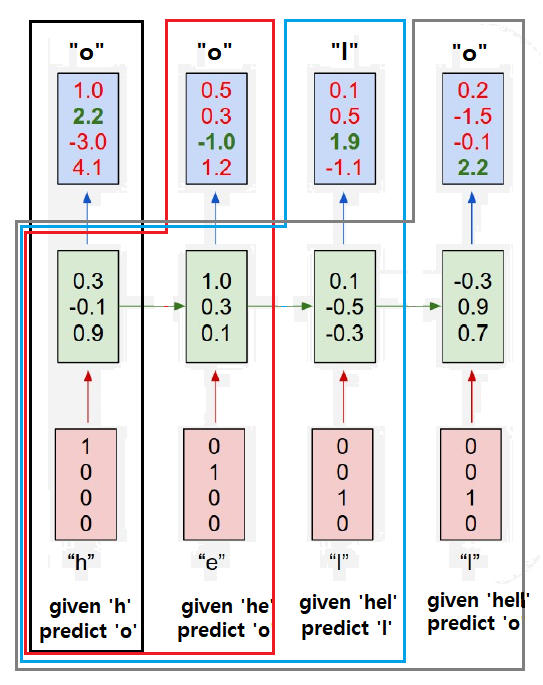
위 그림이 의미하는 것은
매번 새로운 input data를 입력할 때마다
이전 시점의 hidden state의 정보가 반영된 예측이 출력된다는 것이다.
이로부터 역전파시에는 기울기가 어떤 순서로 어디에 역전파되는지를 그려볼 수 있다.
3. Embedding layer의 역할은
Weight matrix와 input data(one-hot vector corresponding to an element in vocabulary)의 행렬곱 연산 대신
Weight matrix에서 특정 Embedding vector를 추출하는 연산을 수행한다.
Weight matrix에 one-hot vector (input data : Xt) 를 곱한다는 건 무엇을 의미하는 걸까?
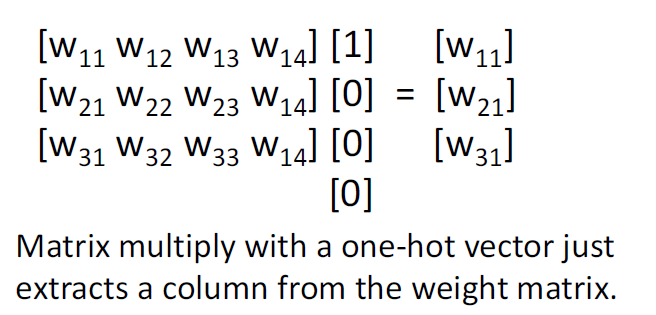
즉 연산의 효율을 높이기 위해 Embedding layer를 사용하는 것이다.
하지만 비단 이 이유만은 아니다.
word2vec의 분산표현 참고 questionet.tistory.com/28?category=961868
2. backward pass는 다음과 같이 이뤄진다.
1. one time step에서 역전파는 다음과 같다.
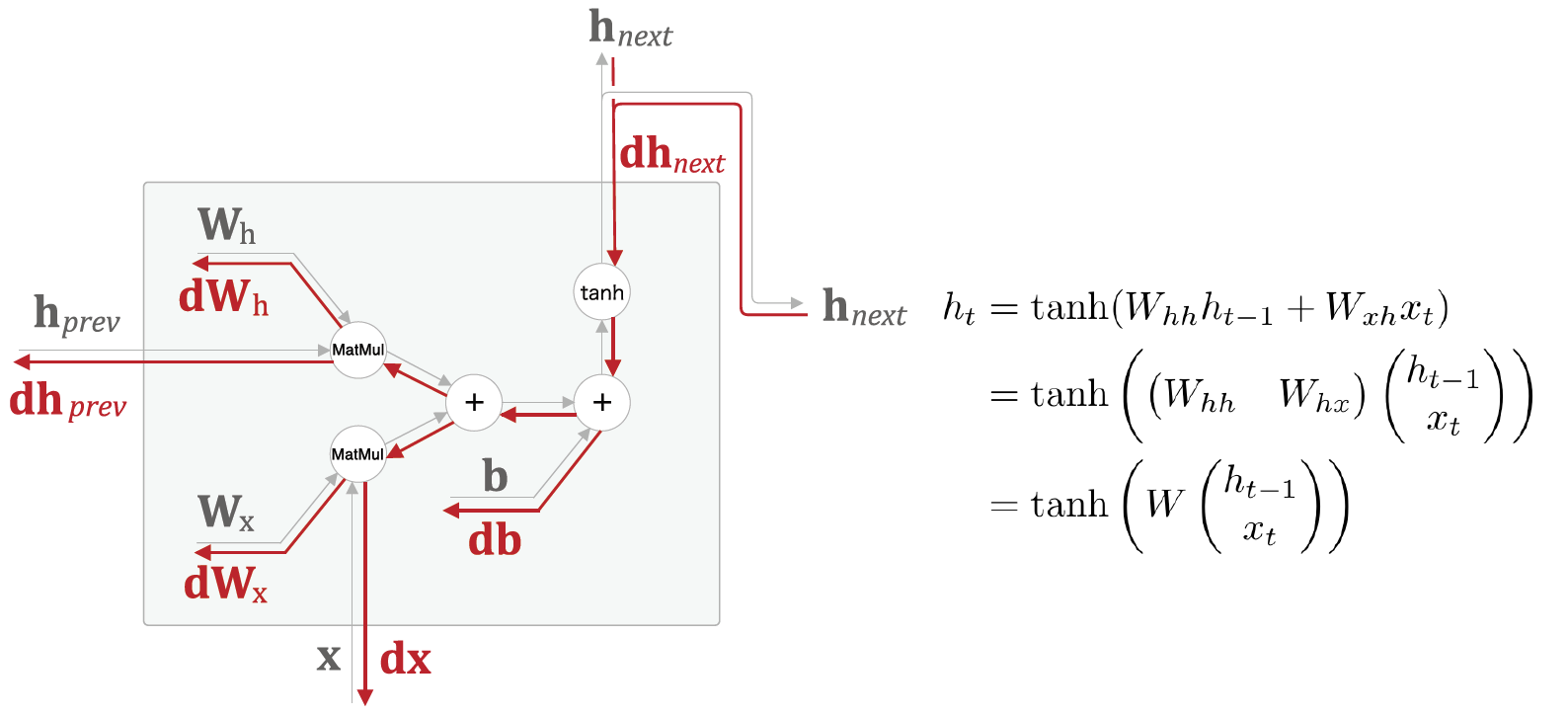
2. 위에서 예로 든 모델의 경우 총 네 가지 경로로 W의 업데이트가 일어난다.
final loss > L1 > y1 > h1, x1 의 W
final loss > L2 > y2 > h2, x2, h1, x1 의 W
final loss > L3 > y3 > h3, x3, h2, x2, h1, x1 의 W
final loss > L4 > y4 > h4, x4, h3, x3, h2, x2, h1, x1 의 W
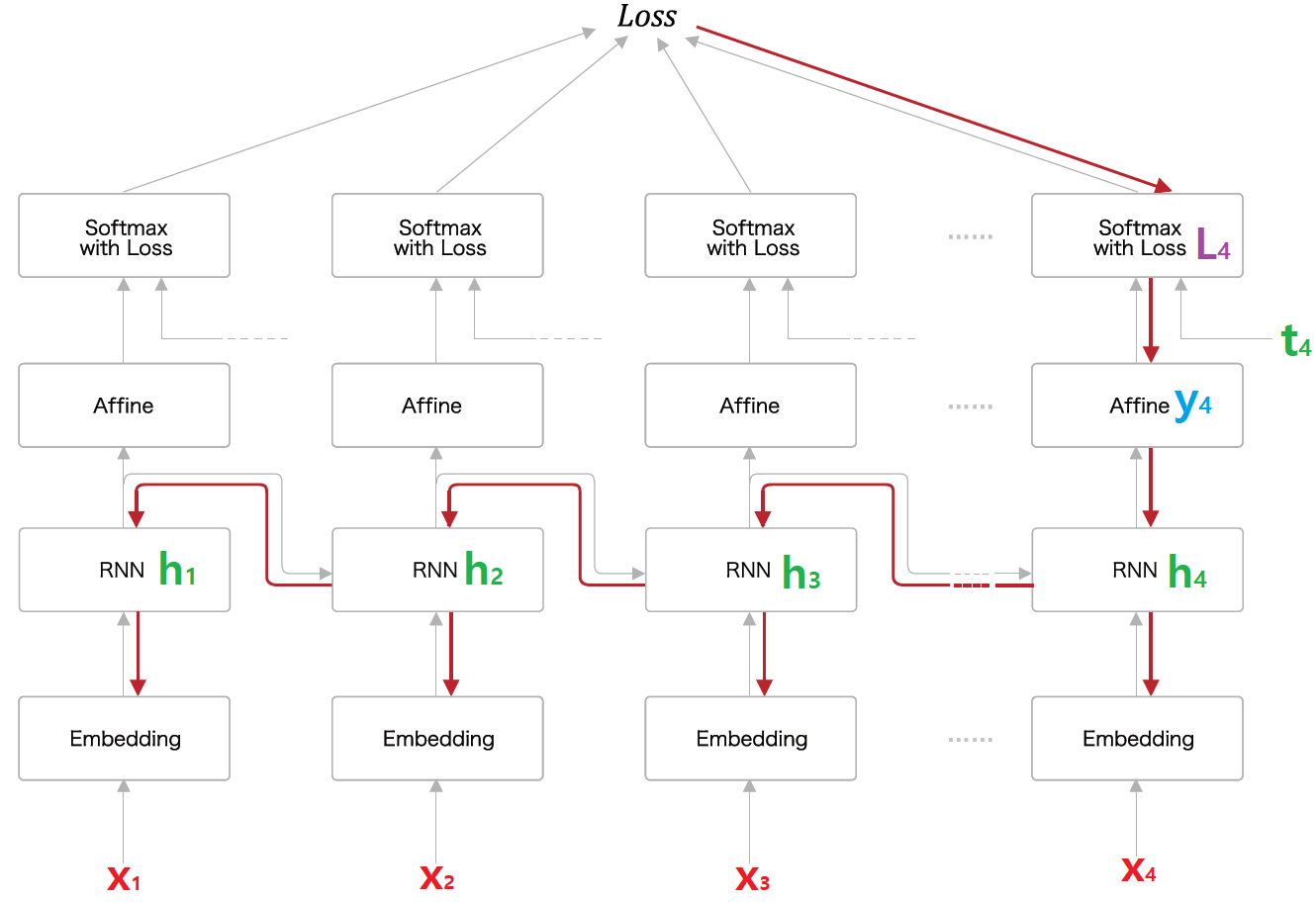
학습시 길이가 매우 긴 Sequence를 처음부터 끝까지 왕복하는 경우 몇 가지 문제가 발생한다.

1. 역전파시 메모리를 엄청 잡아먹게 된다는 점.
2. 더불어 gradients vanishing or exploding이 일어날 확률이 높아진다는 점.
gradients vanishing or exploding은 왜 일어날까?
RNN의 역전파에서 거치게 되는 주요한 노드는 tanh 와 matmul 노드다.


tanh함수를 통과할 때부터 살펴보자.
tanh 함수의 미분값은 0과 1사이가 되고,
특히 x가 0에서 멀어질수록 작아진다.
따라서 upstream gradient인 dh와
local gradient인 tanh의 미분값을 곱한
downstream gradient는
tanh 노드를 거칠 때마다 점점 작아진다.

한편, matmul 노드에서는
upstream gradient인 dh가 matmul노드를 지날때마다
local gradient인 Wh의 전치행렬을 곱한 값이
downstream gradient가 되어 계속 역전파 돼 나간다.
이 행렬곱 연산은 이전 시점의 계층을 지나갈 때마다 일어나는데
여기서 곱해지는 Wh는 모든 계층에 동일하다.
여기서 Wh 행렬의 largest singular value(여러 특이값 중 최대값)이 1보다 크면
기울기가 지수적으로 증가해 기울기 폭발이 일어나고
1보다 작으면 지수적으로 감소해 기울기소실이 일어나는 것이다.
이에 대한 해결책은 여러가지가 있는데
첫번째로 Truncated BackPropagation Through Time이 있다.

Truncated BPTT는
순전파에선 whole sequence를 그대로 forward pass하되
역전파시에는 whole sequence를 일정한 단위의 chunk로 나눈 다음
첫번째 chunk에서 순전파와 역전파를 거듭하여
첫번째 chunk의 마지막 hidden state에 그 앞 부분까지 학습된 weights를 다음 chunk로 전달하고
이런 식으로 마지막 chunk의 마지막 hidden state까지 반복 진행하여
W를 업데이트하는 방법이다.
Truncated BackPropagation Through Time을 하면 역전파시 정보의 손실이 일어난다
두번째로 기울기 클립핑 gradients clipping이 있다.
기울기의 크기(L2 norm)이 임계치(threshold)를 넘어가면
threshold를 L2 norm으로 나눈 값을 기울기에 곱해
그 값을 기울기로 사용하는 방법이다.
이건 기울기 폭발을 막기 위한 고육지책으로서
기울기에 인위적으로 손을 댄다는 점에서 봤을 땐 썩 좋은 방법은 아니다.
하지만 기울기가 폭발하는 것보단 나으므로 실제로 사용되는 방법 중 하나다.
세번째로 Vanilla RNN 모델을 버리고 새로운 모델을 쓰는 방법이 있다.
바로 LSTM과 GRU다.
두 모델은 기울기 소실 문제를 해결하는 데 기여하는 Gate들이 RNN 계층에 추가된 모델이다.
더 자세한 내용은 LSTM, GRU 에서 계속 questionet.tistory.com/37?category=961868
Vanilla RNN도 다른 딥러닝 모델처럼 층을 깊게 할 수 있다.
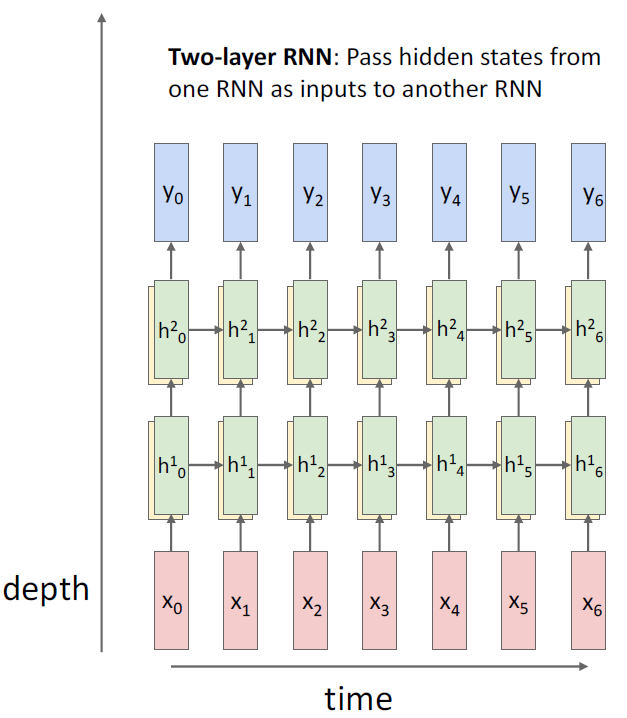
첫번째 layer와 두번째 layer는
대개 서로 다른 weight matrix를 사용한다.
RNN은 CNN과는 다르게 층을 아주 깊게 쌓진 않는다.
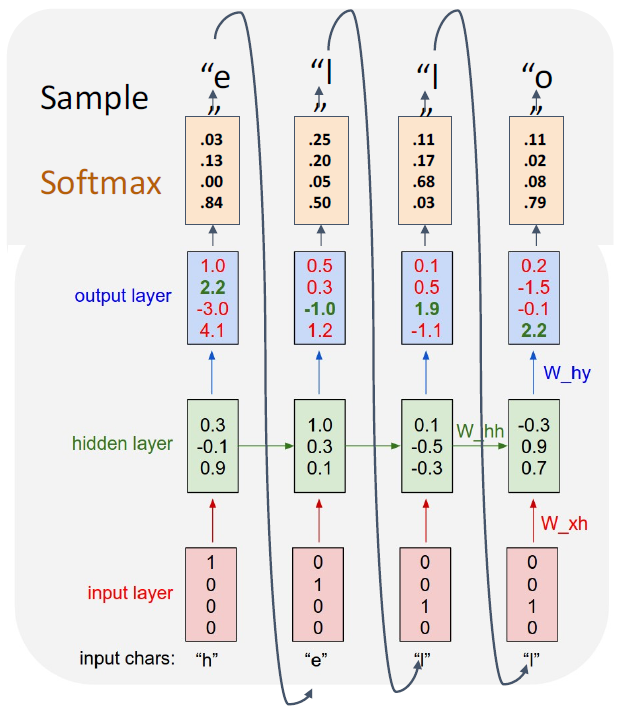
그렇다면 어찌됐든 완성된 Vanilla RNN 모델로
무엇을 할 수 있을까?
Many - to - Many problem을 다루는
Seq2seq 모델이라면
디코더의 매 시점에 나온 출력을
다음 시점의 입력으로 써서
문장을 생성하게 할 수 있을 것이다.
'Deep learning > NLP 모델 설명' 카테고리의 다른 글
| RWKV, (0) | 2024.01.31 |
|---|---|
| Attention, self-attention, transformer (1) | 2021.03.14 |
| WordNet (0) | 2021.02.25 |
| LSTM, GRU (0) | 2021.02.25 |

